Maintain RAG embeddings with OpenAI, Postgres and auto drift rollback
Workflow preview
DISCOUNT 20%
Overview
Overview
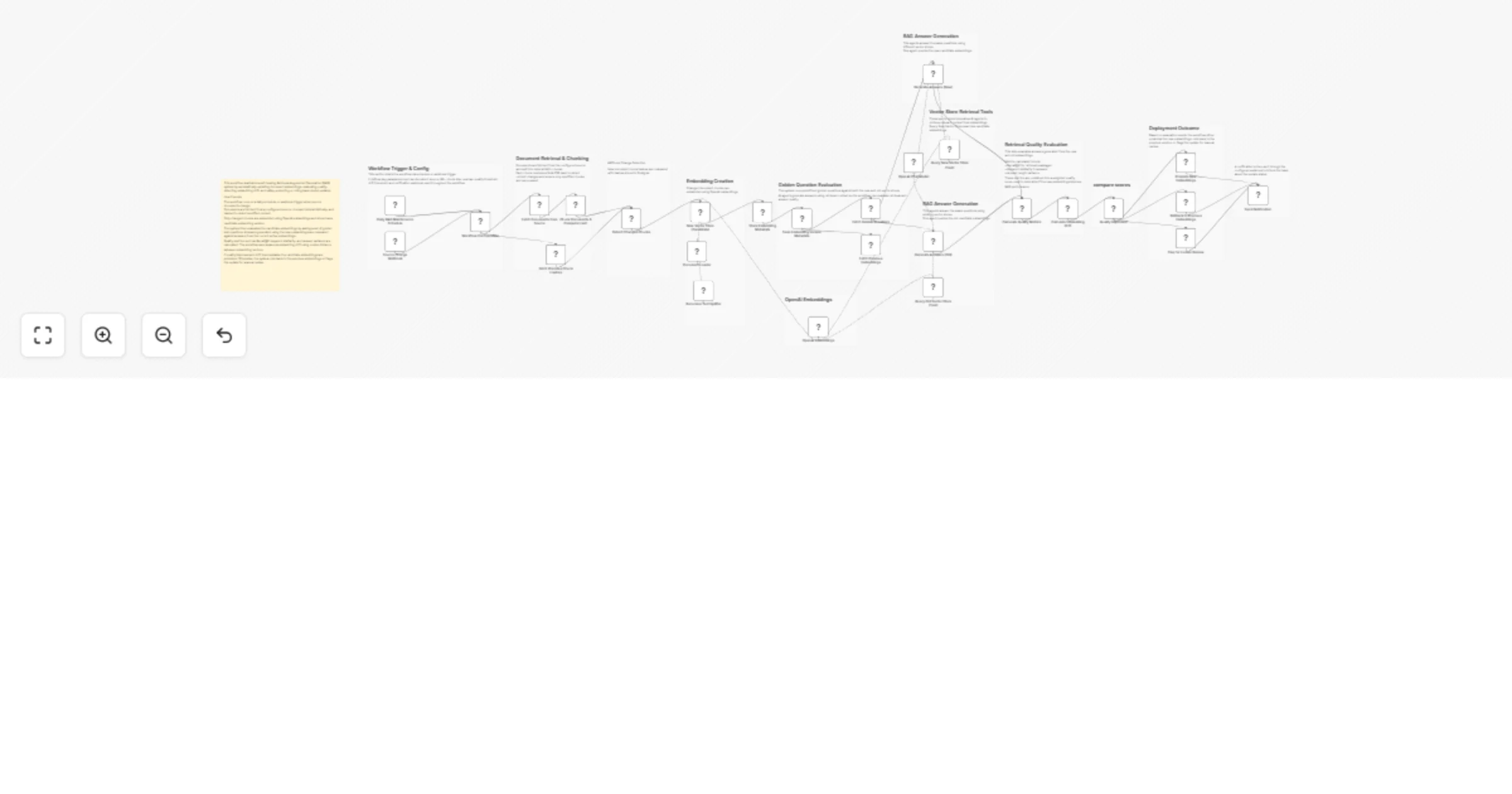
This workflow implements a self-healing Retrieval-Augmented Generation (RAG) maintenance system that automatically updates document embeddings, evaluates retrieval quality, detects embedding drift, and safely promotes or rolls back embedding updates.
Maintaining high-quality embeddings in production RAG systems is difficult. When source documents change or embedding models evolve, updates can accidentally degrade retrieval quality or introduce semantic drift.
This workflow solves that problem by introducing an automated evaluation and rollback pipeline for embeddings.
It periodically checks for document changes, regenerates embeddings for updated content, evaluates the new embeddings against a set of predefined golden test questions, and compares the results with the currently active embeddings.
Quality metrics such as Recall@K, keyword similarity, and answer variance are calculated, while embedding vectors are also analyzed for semantic drift using cosine distance.
If the new embeddings outperform the current ones and remain within acceptable drift limits, they are automatically promoted to production. Otherwise, the system safely rolls back or flags the update for manual review.
This creates a robust, production-safe RAG lifecycle automation system.
How It Works
1. Workflow Trigger
The workflow can start in two ways:
- Scheduled trigger running daily
- Webhook trigger when source documents change
Both paths lead to a centralized configuration node that defines parameters such as chunk size, thresholds, and notification settings.
2. Document Retrieval & Change Detection
Documents are fetched from the configured source (GitHub, Drive, Confluence, or other APIs).
The workflow then:
- Splits documents into deterministic chunks
- Computes SHA-256 hashes for each chunk
- Compares them with previously stored hashes in Postgres
Only new or modified chunks proceed for embedding generation, which significantly reduces processing cost.
3. Embedding Generation
Changed chunks are processed through:
- Recursive text splitting
- Document loading
- OpenAI embedding generation
These embeddings are stored as a candidate vector store rather than immediately replacing the production embeddings.
Metadata about the embedding version is stored in Postgres.
4. Golden Question Evaluation
A set of golden test questions stored in the database is used to evaluate retrieval quality.
Two AI agents are used:
- One queries the candidate embeddings
- One queries the current production embeddings
Both generate answers using retrieved context.
5. Quality Metrics Calculation
The workflow calculates several evaluation metrics:
- Recall@K to measure retrieval effectiveness
- Keyword similarity between generated answers and expected answers
- Answer length variance to detect inconsistencies
These are combined into a weighted quality score.
6. Embedding Drift Detection
The workflow compares embedding vectors between versions using cosine distance.
This identifies semantic drift, which may occur due to:
- embedding model updates
- chunking changes
- document structure changes
7. Promotion or Rollback
The workflow checks two conditions:
- Quality score exceeds the configured threshold
- Embedding drift remains below the drift threshold
If both conditions pass:
- The candidate embeddings are promoted to active
If not:
- The system rolls back to the previous embeddings
- Or flags the update for human review
8. Notifications
A webhook notification is sent with:
- update status
- quality score
- drift score
- timestamp
This allows teams to monitor embedding health automatically.
Setup Instructions
- Configure Document Source
Edit the Workflow Configuration node and set:
documentSourceUrlAPI endpoint or file source containing your documents.
Examples include:
- GitHub repository API
- Google Drive export API
- Confluence REST API
- Configure Postgres Database
Create the following tables in your Postgres database:
document_chunksembeddingsembedding_versionsgolden_questions
These tables store chunk hashes, embedding vectors, version metadata, and evaluation questions.
Connect the Postgres nodes using your database credentials.
- Add OpenAI Credentials
Configure credentials for:
- OpenAI Embeddings
- OpenAI Chat Model
These are used for generating embeddings and answering evaluation questions.
- Populate Golden Questions
Insert evaluation questions into the golden_questions table.
Each record should include:
question_text- expected passages
- expected answer keywords
These questions represent critical queries your RAG system must answer correctly.
- Configure Notification Webhook
Add a Slack or Teams webhook URL in the configuration node.
Notifications will be sent whenever:
- embeddings are promoted
- embeddings are rolled back
- manual review is required
- Adjust Quality Thresholds
In the configuration node you can modify:
qualityThresholddriftThresholdchunkSizechunkOverlap
These parameters control the sensitivity of the evaluation system.
Use Cases
Production RAG Monitoring
Automatically evaluate and update embeddings in production knowledge systems without risking degraded results.
Continuous Knowledge Base Updates
Keep embeddings synchronized with frequently changing documentation, repositories, or internal knowledge bases.
Safe Embedding Model Upgrades
Test new embedding models against production data before promoting them.
AI System Reliability
Detect retrieval regressions before they affect end users.
Enterprise AI Governance
Provide automated evaluation and rollback capabilities for mission-critical RAG deployments.
Requirements
This workflow requires the following services:
- n8n
- Postgres Database
- OpenAI API
Recommended integrations:
- Slack or Microsoft Teams (for notifications)
Required nodes include:
- Schedule Trigger
- Webhook
- HTTP Request
- Postgres
- Compare Datasets
- Code nodes
- OpenAI Embeddings
- OpenAI Chat Model
- Vector Store nodes
- AI Agent nodes
Summary
This workflow provides a fully automated self-healing RAG infrastructure for maintaining embedding quality in production systems.
By combining change detection, golden-question evaluation, embedding drift analysis, and automatic rollback, it ensures that retrieval performance improves safely over time.
It is ideal for teams running production AI assistants, knowledge bases, or internal search systems that depend on high-quality vector embeddings.