Evaluate AI agent response correctness with OpenAI and RAGAS methodology
Workflow preview
$20/month : Unlimited workflows
2500 executions/month
THE #1 IN WEB SCRAPING
Scrape any website without limits
HOSTINGER  Early Deal
Early Deal
DISCOUNT 20% Try free
DISCOUNT 20%
Self-hosted n8n
Unlimited workflows - from $4.99/mo
#1 hub for scraping, AI & automation
6000+ actors - $5 credits/mo
Important notice
This workflow is provided as-is. Please review and test before using in production.
Overview
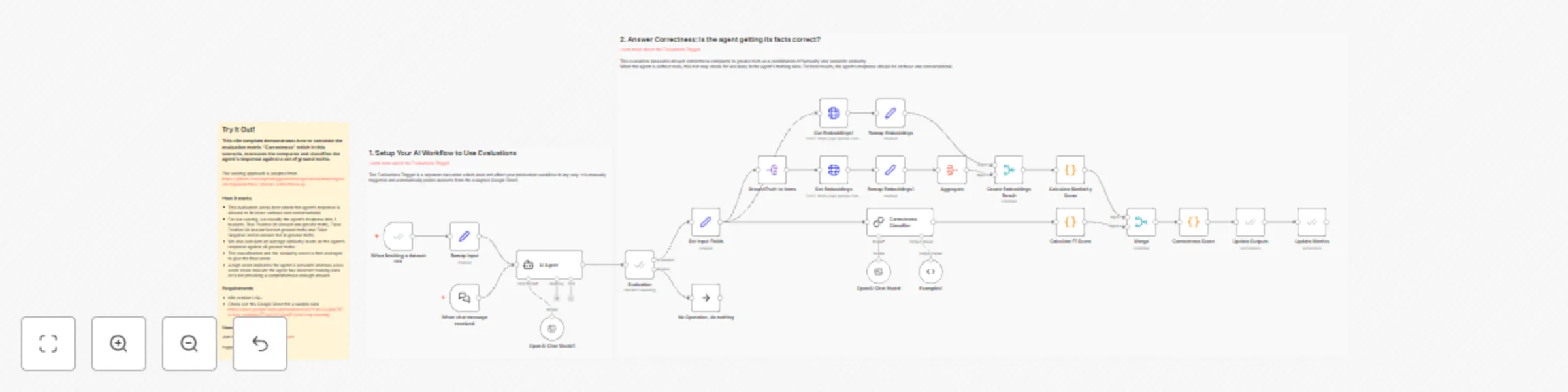
This n8n template demonstrates how to calculate the evaluation metric "Correctness" which in this scenario, measures the compares and classifies the agent's response against a set of ground truths.
The scoring approach is adapted from the open-source evaluations project RAGAS and you can see the source here https://github.com/explodinggradients/ragas/blob/main/ragas/src/ragas/metrics/_answer_correctness.py
How it works
- This evaluation works best where the agent's response is allowed to be more verbose and conversational.
- For our scoring, we classify the agent's response into 3 buckets: True Positive (in answer and ground truth), False Positive (in answer but not ground truth) and False Negative (not in answer but in ground truth).
- We also calculate an average similarity score on the agent's response against all ground truths.
- The classification and the similarity score is then averaged to give the final score.
- A high score indicates the agent is accurate whereas a low score could indicate the agent has incorrect training data or is not providing a comprehensive enough answer.
Requirements
- n8n version 1.94+
- Check out this Google Sheet for a sample data https://docs.google.com/spreadsheets/d/1YOnu2JJjlxd787AuYcg-wKbkjyjyZFgASYVV0jsij5Y/edit?usp=sharing