Deduplicate data records using JavaScript array methods
Workflow preview
DISCOUNT 20%
Important notice
This workflow is provided as-is. Please review and test before using in production.
Overview
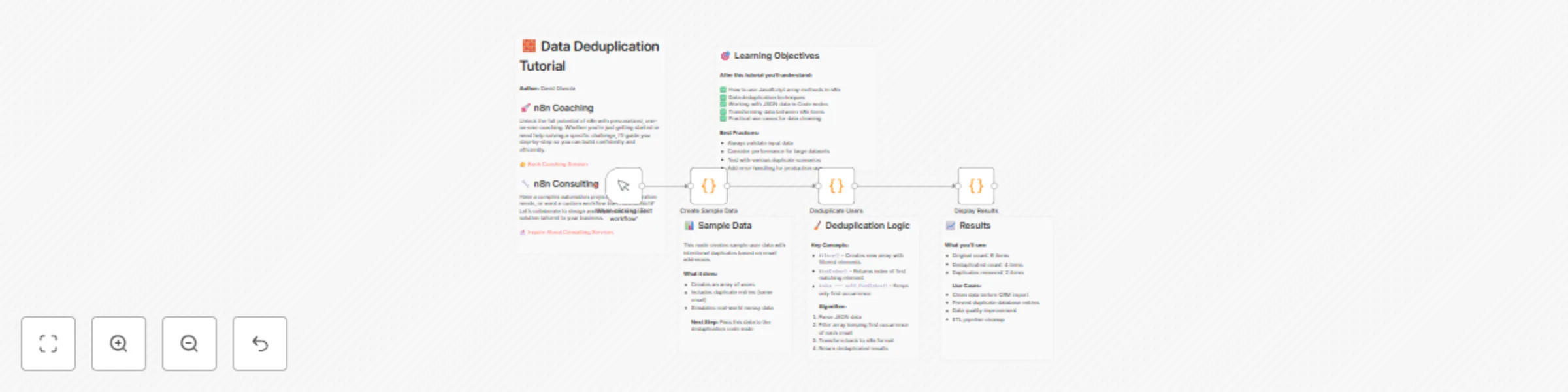
How It Works – Data Deduplication in n8n
This tutorial demonstrates how to remove duplicate records from a dataset using JavaScript logic inside n8n's Code nodes. It simulates real-world data cleaning by generating sample user data with intentional duplicates (based on email addresses) and walks you through the process of deduplication step-by-step.
The process includes:
Creating Sample Data with duplicates. Filtering Out Duplicates using filter() and findIndex() based on email. Displaying Cleaned Results with simple statistics for before-and-after comparison. This is ideal for scenarios like CRM imports, ETL processes, and general data hygiene.
⚙️ Set-Up Steps
🔹 Step 1: Manual Trigger Node: When clicking 'Test workflow' Purpose: Initiates the workflow manually for testing.
🔹 Step 2: Generate Sample Data Node: Create Sample Data (Code node) What it does:
Creates 6 users, including 2 intentional duplicates (by email). Outputs data as usersJson with metadata (totalCount, message). Mimics real-world messy datasets. 🔹 Step 3: Deduplicate the Data Node: Deduplicate Users (Code node) What it does:
Parses usersJson. Uses .filter() + .findIndex() to keep only the first instance of each email. Logs total, unique, and removed counts. Outputs clean user list as separate items. 🔹 Step 4: Display Results Node: Display Results (Code node) What it does:
Outputs structured summary: Unique users Status Timestamp Prepares results for review or downstream use. 📈 Sample Output
Original count: 6 users Deduplicated count: 4 users Duplicates removed: 2 users 🎯 Learning Objectives
You'll learn how to:
Use .filter() and .findIndex() in n8n Code nodes Clean JSON data within workflows Create simple, effective deduplication pipelines Output structured summaries for reporting or integration 🧠Best Practices
Validate input format (e.g., JSON schema) Handle null or missing fields gracefully Use logging for visibility Add error handling for production use Use pagination/chunking for large datasets