Daily RAG research paper hub with arXiv, Gemini AI, and Notion
Workflow preview
DISCOUNT 20%
Important notice
This workflow is provided as-is. Please review and test before using in production.
Overview
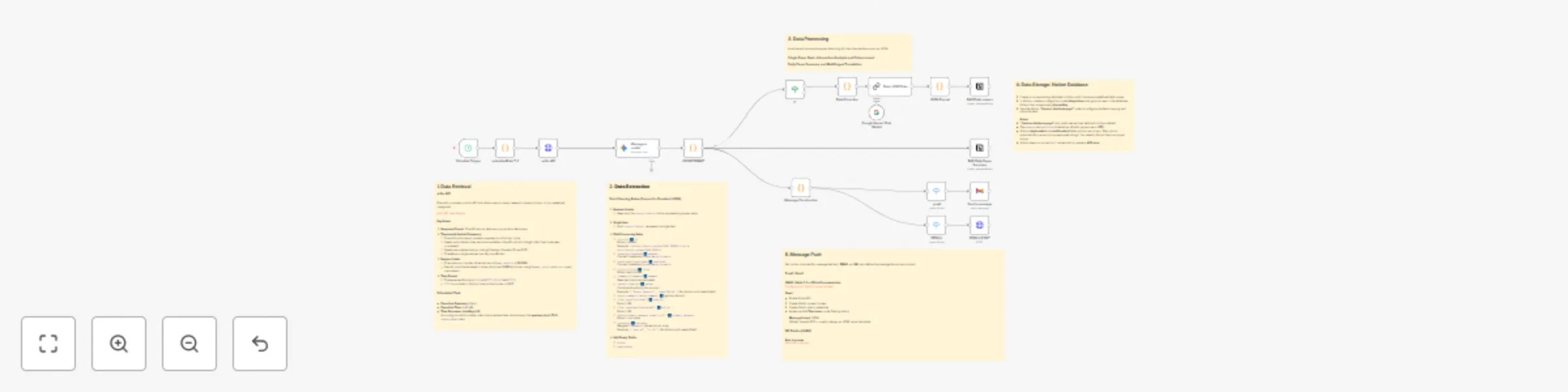
Fetch user-specific research papers from arXiv on a daily schedule, process and structure the data, and create or update entries in a Notion database, with support for data delivery
- Paper Topic: single query keyword
- Update Frequency: Daily updates, with fewer than 20 entries expected per day
- Tools:
- Platform: n8n, for end-to-end workflow configuration
- AI Model: Gemini-2.5-Flash, for daily paper summarization and data processing
- Database: Notion, with two tables — Daily Paper Summary and Paper Details
- Message: Feishu (IM bot notifications), Gmail (email notifications)
1. Data Retrieval
arXiv API
The arXiv provides a public API that allows users to query research papers by topic or by predefined categories.
Key Notes:
- Response Format: The API returns data as a typical Atom Response.
- Timezone & Update Frequency:
- The arXiv submission process operates on a 24-hour cycle.
- Newly submitted articles become available in the API only at midnight after they have been processed.
- Feeds are updated daily at midnight Eastern Standard Time (EST).
- Therefore, a single request per day is sufficient.
- Request Limits:
- The maximum number of results per call (
max_results) is 30,000, - Results must be retrieved in slices of at most 2,000 at a time, using the
max_resultsandstartquery parameters.
- The maximum number of results per call (
- Time Format:
- The expected format is
[YYYYMMDDTTTT+TO+YYYYMMDDTTTT], TTTTis provided in 24-hour time to the minute, in GMT.
- The expected format is
Scheduled Task
- Execution Frequency: Daily
- Execution Time: 6:00 AM
- Time Parameter Handling (JS):
According to arXiv’s update rules, the scheduled task should query the previous day’s (T-1)submittedDatedata.
2. Data Extraction
Data Cleaning Rules (Convert to Standard JSON)
Remove Header
- Keep only the 【entry】【/entry】 blocks representing paper items.
Single Item
- Each 【entry】【/entry】 represents a single item.
Field Processing Rules
【id】【/id】 ➡️ id
Extract content.
Example:
【id】http://arxiv.org/abs/2409.06062v1【/id】 → http://arxiv.org/abs/2409.06062v1【updated】【/updated】 ➡️ updated
Convert timestamp toyyyy-mm-dd hh:mm:ss【published】【/published】 ➡️ published
Convert timestamp toyyyy-mm-dd hh:mm:ss【title】【/title】 ➡️ title
Extract text content【summary】【/summary】 ➡️ summary
Keep text, remove line breaks【author】【/author】 ➡️ author
Combine all authors into an array
Example:[ "Ernest Pusateri", "Anmol Walia" ](for Notion multi-select field)【arxiv:comment】【/arxiv:comment】 ➡️ Ignore / discard
【link type="text/html"】 ➡️ html_url
Extract URL【link type="application/pdf"】 ➡️ pdf_url
Extract URL【arxiv:primary_category term="cs.CL"】 ➡️ primary_category
Extracttermvalue【category】 ➡️ category
Merge all 【category】 values into an array
Example:[ "eess.AS", "cs.SD" ](for Notion multi-select field)
Add Empty Fields
githubhuggingface
3. Data Processing
Analyze and summarize paper data using AI, then standardize output as JSON.
- Single Paper Basic Information Analysis and Enhancement
- Daily Paper Summary and Multilingual Translation
4. Data Storage: Notion Database
- Create a corresponding database in Notion with the same predefined field names.
- In Notion, create an integration under Integrations and grant access to the database. Obtain the corresponding Secret Key.
- Use the Notion "Create a database page" node to configure the field mapping and store the data.
Notes
- "Create a database page" only adds new entries; data will not be updated.
- The
updatedandpublishedtimestamps of arXiv papers are in UTC. - Notion single-select and multi-select fields only accept arrays. They do not automatically parse comma-separated strings. You need to format them as proper arrays.
- Notion does not accept
nullvalues, which causes a 400 error.
5. Data Delivery
Set up two channels for message delivery: EMAIL and IM, and define the message format and content.
Email: Gmail
GMAIL OAuth 2.0 – Official Documentation
Configure your OAuth consent screen
Steps:
- Enable Gmail API
- Create OAuth consent screen
- Create OAuth client credentials
- Audience: Add Test users under Testing status
Message format: HTML
(Model: OpenAI GPT — used to design an HTML email template)
IM: Feishu (LARK)
Bots in groups
Use bots in groups