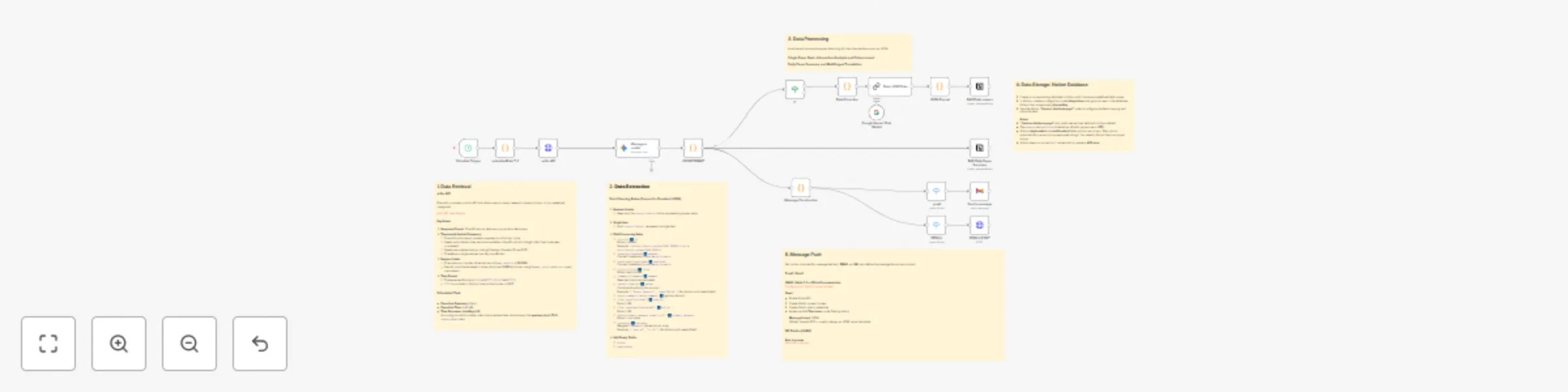
Fetch user specific research papers from arXiv on a daily schedule, process and structure the data, and create or upd...