
Ian Kerins
Workflows by Ian Kerins
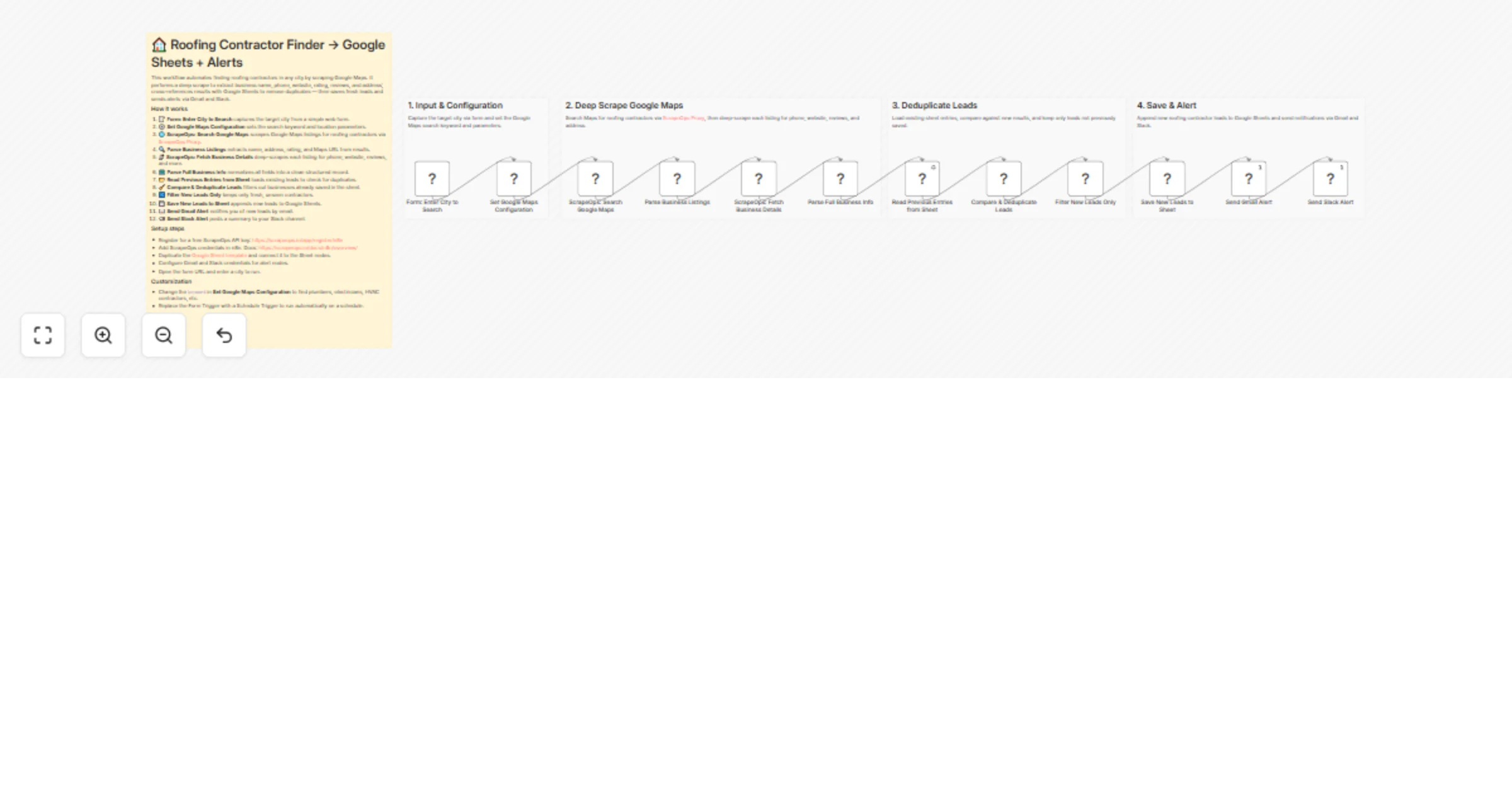
Generate roofing contractor leads from Google Maps with ScrapeOps, Sheets and Slack
Overview This n8n template automates finding roofing contractors in any city using Google Maps. It deep scrapes listi...
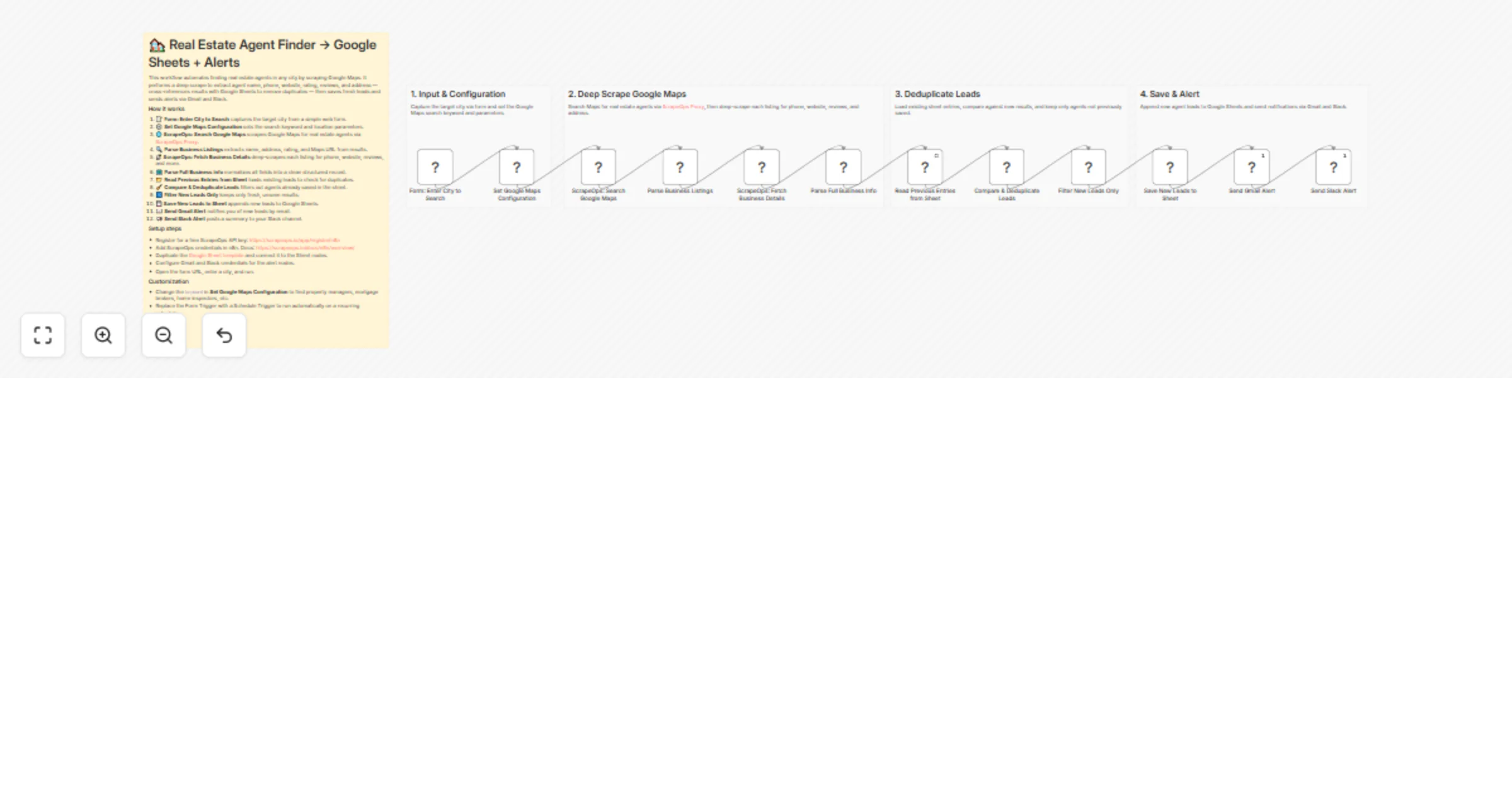
Scrape Google Maps realtor leads with ScrapeOps, Google Sheets, Gmail and Slack
Overview This n8n template automates finding real estate agents in any city using Google Maps. It deep scrapes listin...
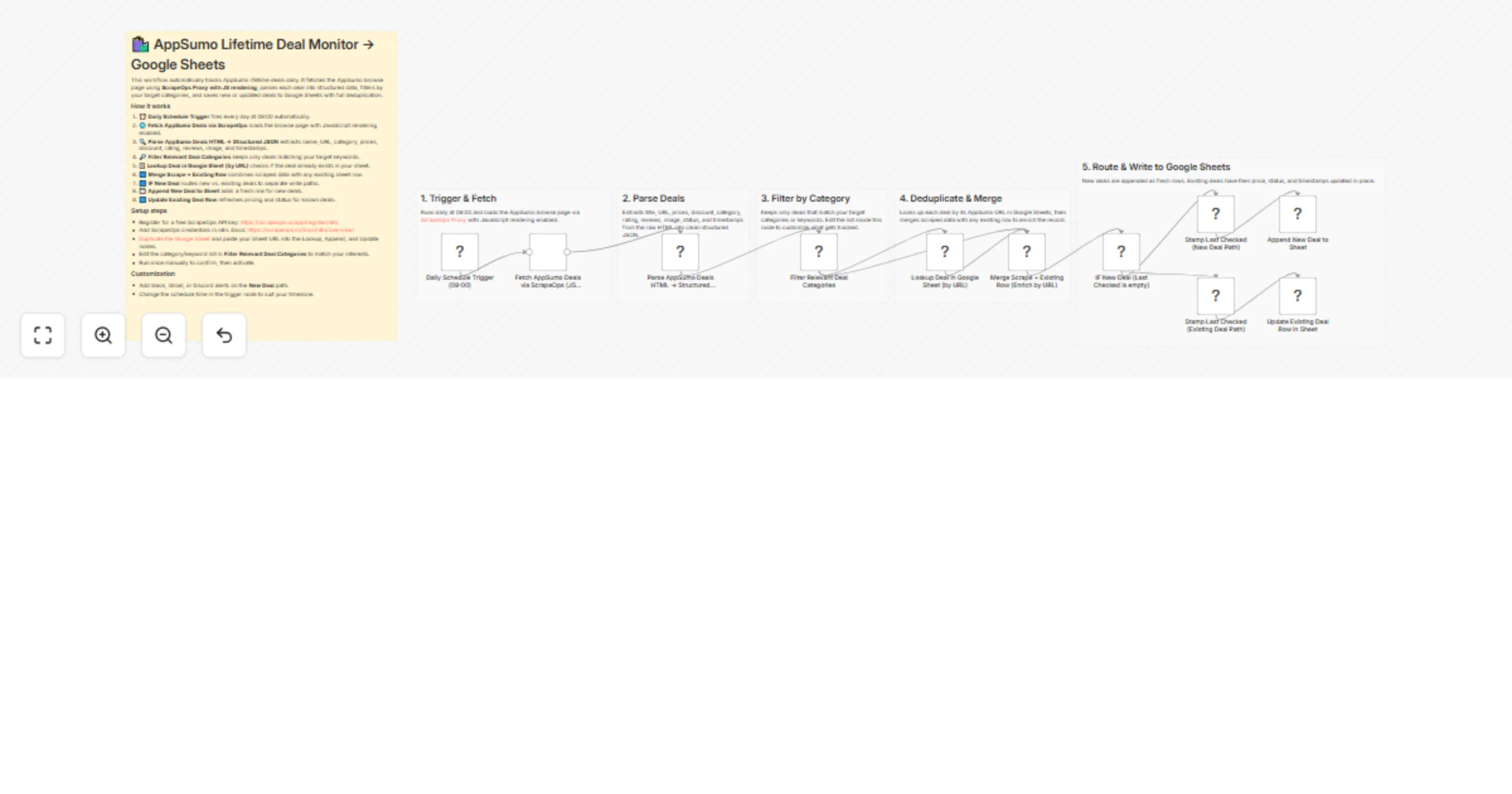
Monitor AppSumo lifetime deals with ScrapeOps and Google Sheets
Overview This n8n template automates daily monitoring of AppSumo lifetime deals. Using ScrapeOps Proxy with JavaScrip...
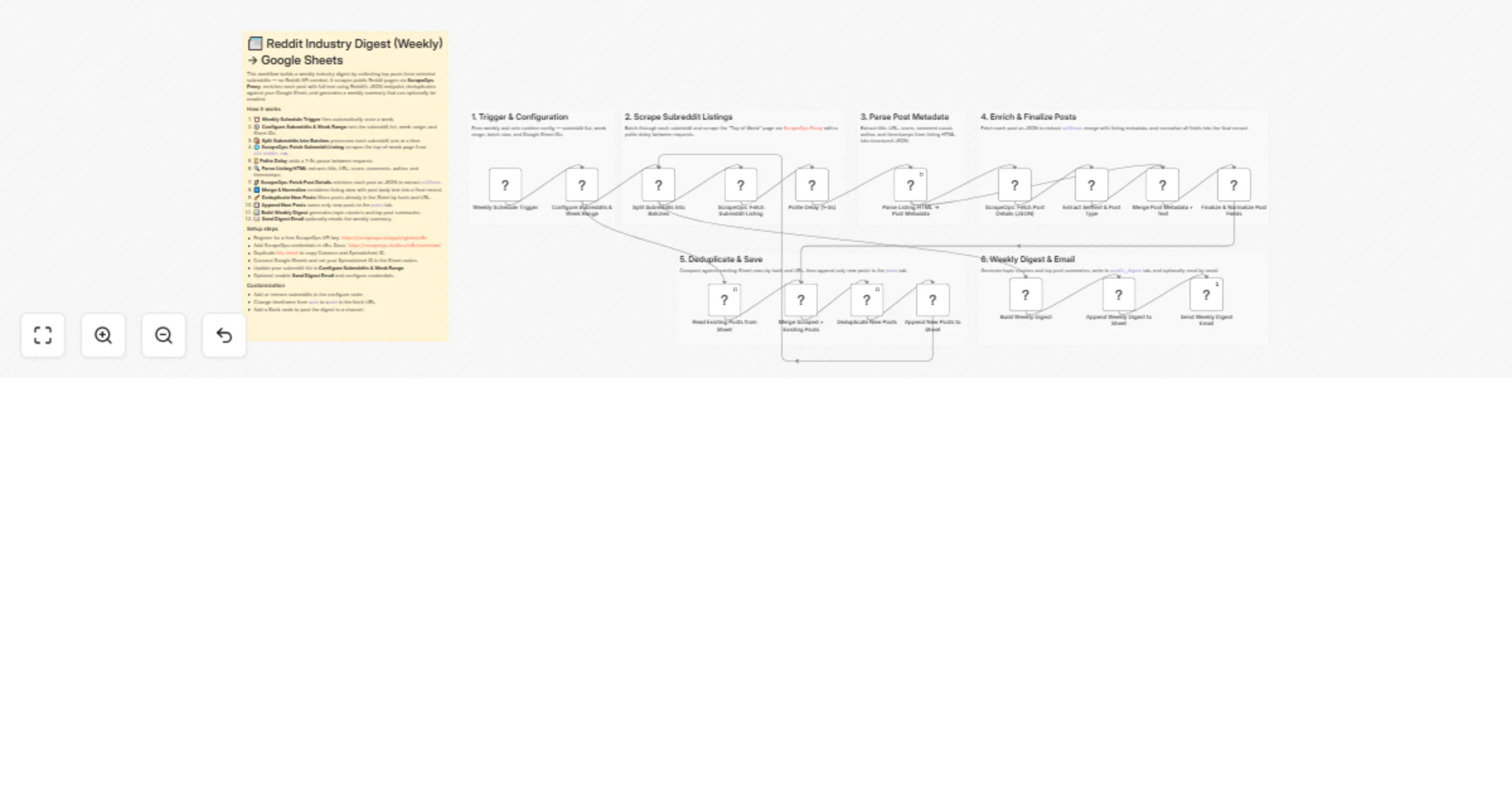
Build a Reddit no-API weekly digest with ScrapeOps and Google Sheets
Overview This n8n template automates a weekly Reddit industry digest without the Reddit API. It scrapes top posts fro...
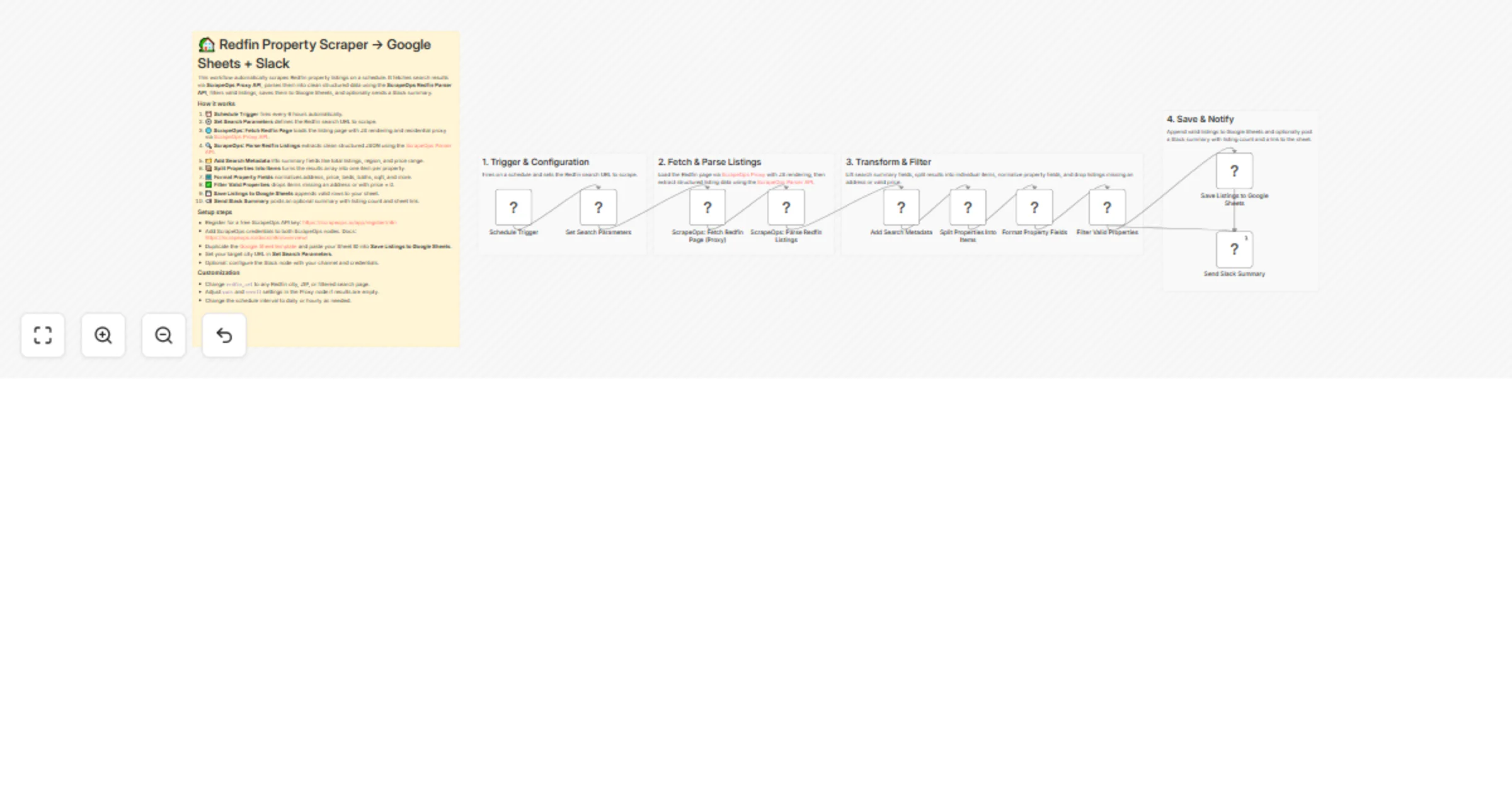
Track Redfin real estate listings with ScrapeOps, Google Sheets, and Slack
Overview This n8n template automates scraping Redfin property listings on a schedule. Using ScrapeOps Proxy API for r...
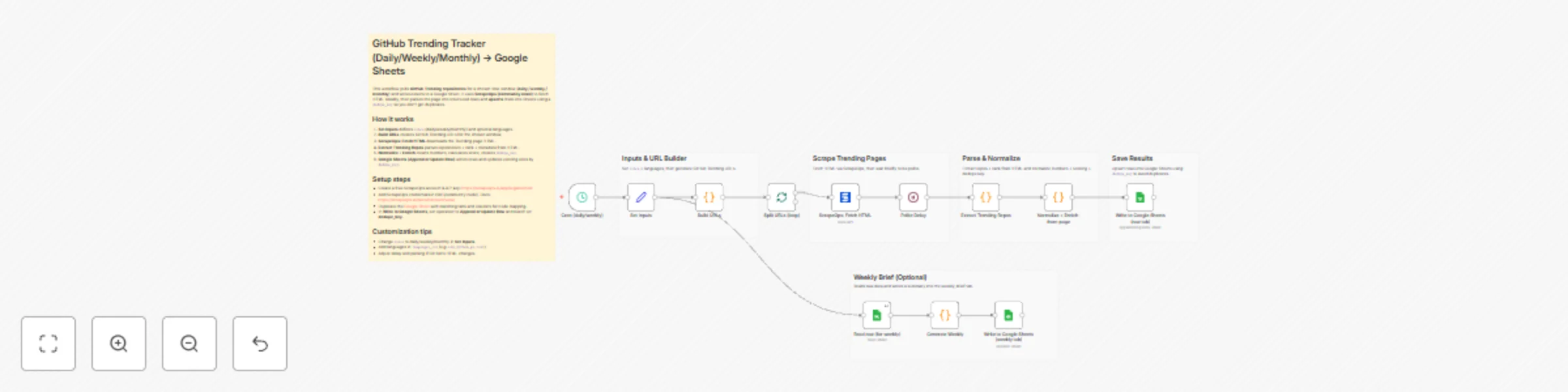
Track GitHub trending repositories with ScrapeOps & Google Sheets
This n8n template tracks GitHub Trending repositories (daily/weekly/monthly), parses the trending page into structure...
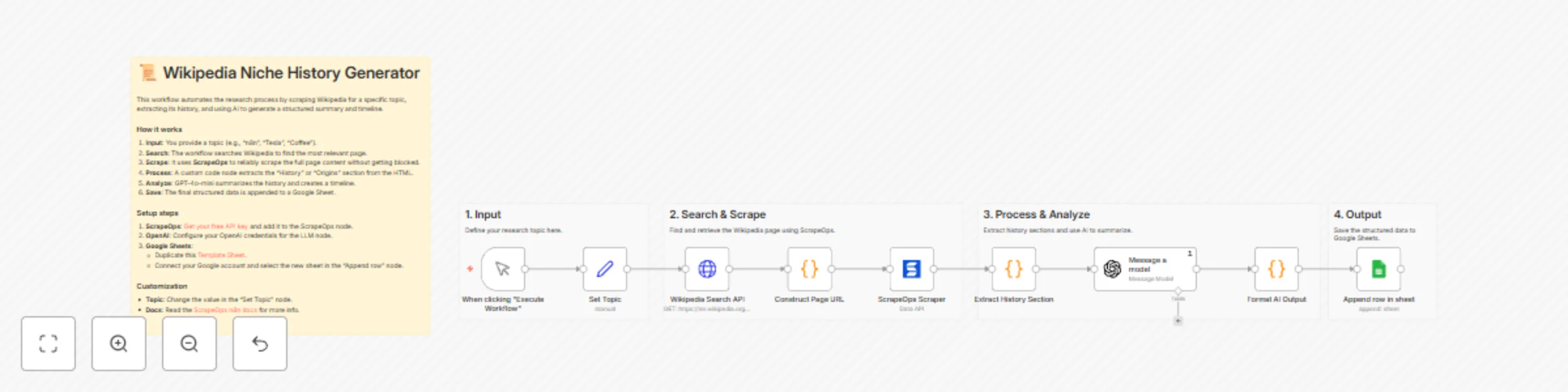
Automate niche research with Wikipedia, GPT-4o-mini, and Google Sheets
This n8n template automates the process of researching niche topics. It searches for a topic on Wikipedia, scrapes th...
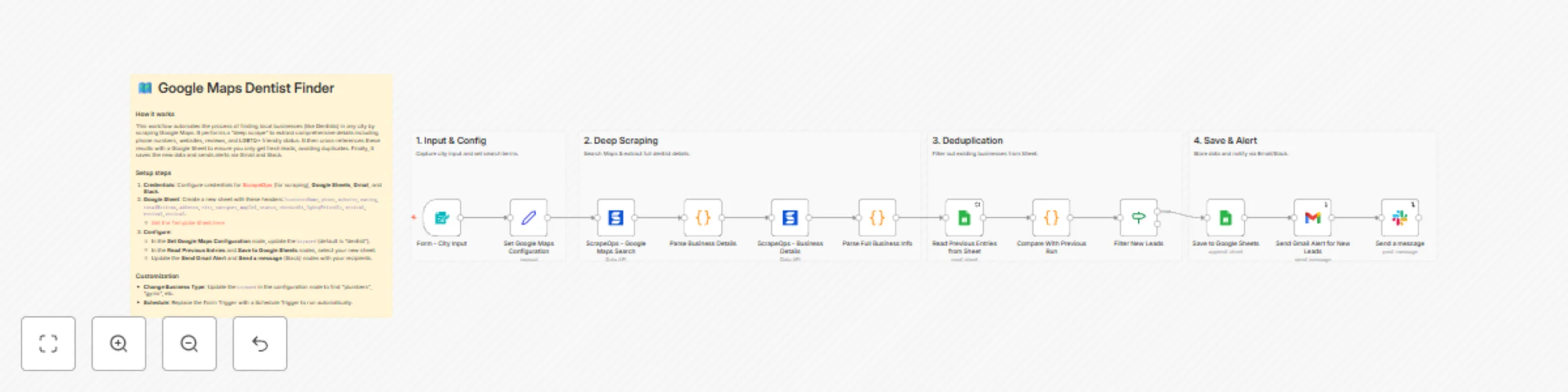
Scrape & track dentist leads from Google Maps with ScrapeOps, Sheets & notifications
This n8n template automates the generation of local business leads by scraping Google Maps. It goes beyond basic sear...
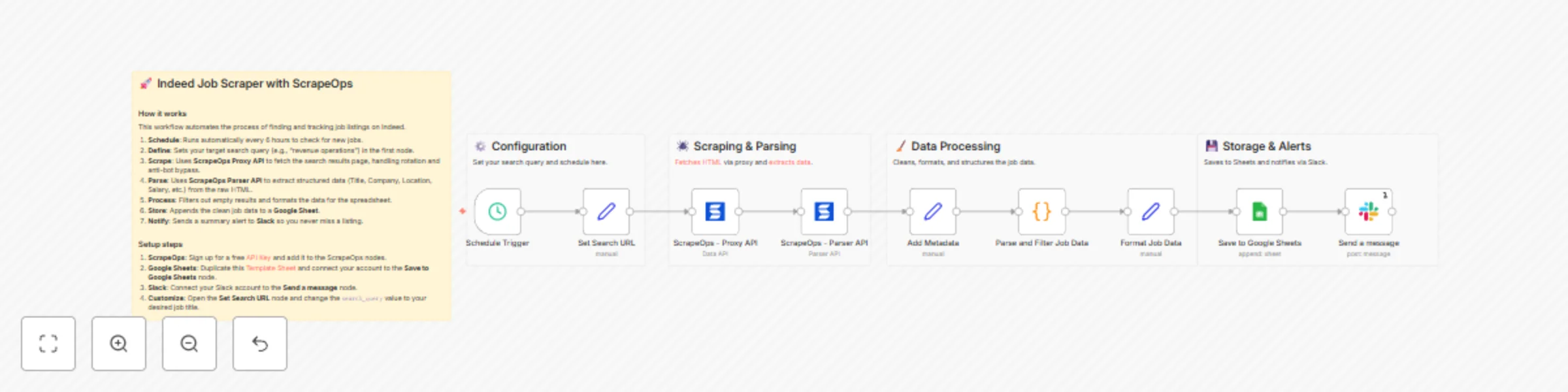
Automate Indeed job tracking with ScrapeOps, Google Sheets & Slack alerts
This n8n template automates the process of scraping job listings from Indeed, parsing the data into a structured form...
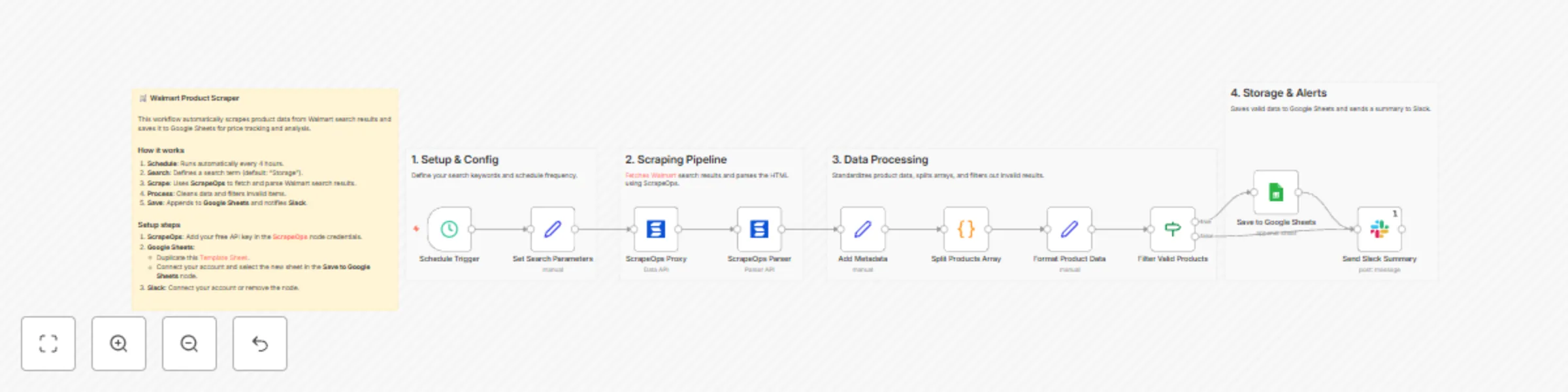
Scheduled Walmart product scraping to Google Sheets with ScrapeOps
This n8n template automates Walmart product discovery and sends clean results to Google Sheets on a fixed schedule (d...