Store Notion's Pages as Vector Documents into Supabase with OpenAI
Workflow preview
$20/month : Unlimited workflows
2500 executions/month
THE #1 IN WEB SCRAPING
Scrape any website without limits
HOSTINGER  Early Deal
Early Deal
DISCOUNT 20% Try free
DISCOUNT 20%
Self-hosted n8n
Unlimited workflows - from $4.99/mo
#1 hub for scraping, AI & automation
6000+ actors - $5 credits/mo
Important notice
This workflow is provided as-is. Please review and test before using in production.
Overview
Workflow updated on 17/06/2024: Added 'Summarize' node to avoid creating a row for each Notion content block in the Supabase table.
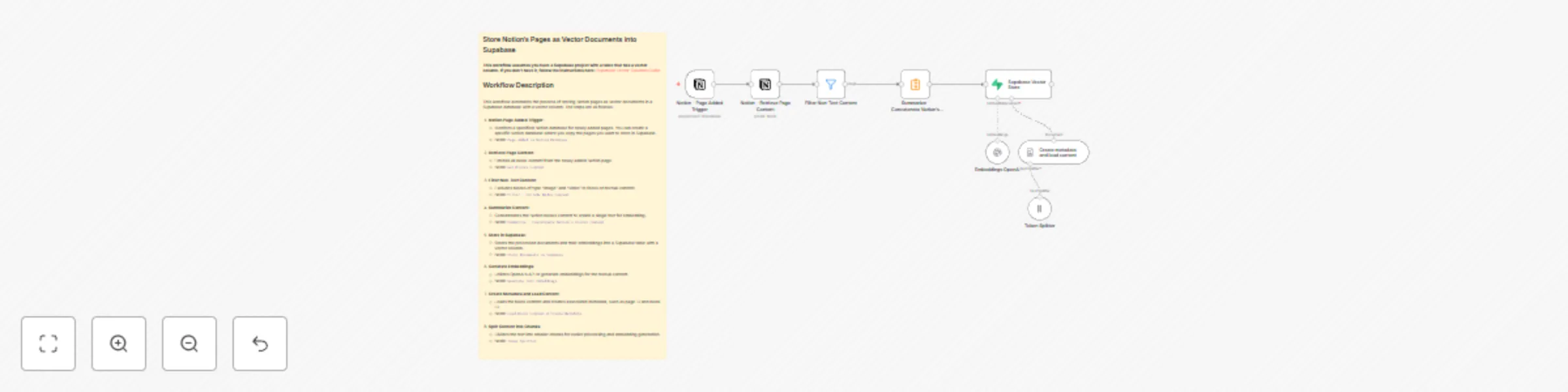
Store Notion's Pages as Vector Documents into Supabase
This workflow assumes you have a Supabase project with a table that has a vector column. If you don't have it, follow the instructions here: Supabase Langchain Guide
Workflow Description
This workflow automates the process of storing Notion pages as vector documents in a Supabase database with a vector column. The steps are as follows:
Notion Page Added Trigger:
- Monitors a specified Notion database for newly added pages. You can create a specific Notion database where you copy the pages you want to store in Supabase.
- Node:
Page Added in Notion Database
Retrieve Page Content:
- Fetches all block content from the newly added Notion page.
- Node:
Get Blocks Content
Filter Non-Text Content:
- Excludes blocks of type "image" and "video" to focus on textual content.
- Node:
Filter - Exclude Media Content
Summarize Content:
- Concatenates the Notion blocks content to create a single text for embedding.
- Node:
Summarize - Concatenate Notion's blocks content
Store in Supabase:
- Stores the processed documents and their embeddings into a Supabase table with a vector column.
- Node:
Store Documents in Supabase
Generate Embeddings:
- Utilizes OpenAI's API to generate embeddings for the textual content.
- Node:
Generate Text Embeddings
Create Metadata and Load Content:
- Loads the block content and creates associated metadata, such as page ID and block ID.
- Node:
Load Block Content & Create Metadata
Split Content into Chunks:
- Divides the text into smaller chunks for easier processing and embedding generation.
- Node:
Token Splitter