
Dataki
Workflows by Dataki
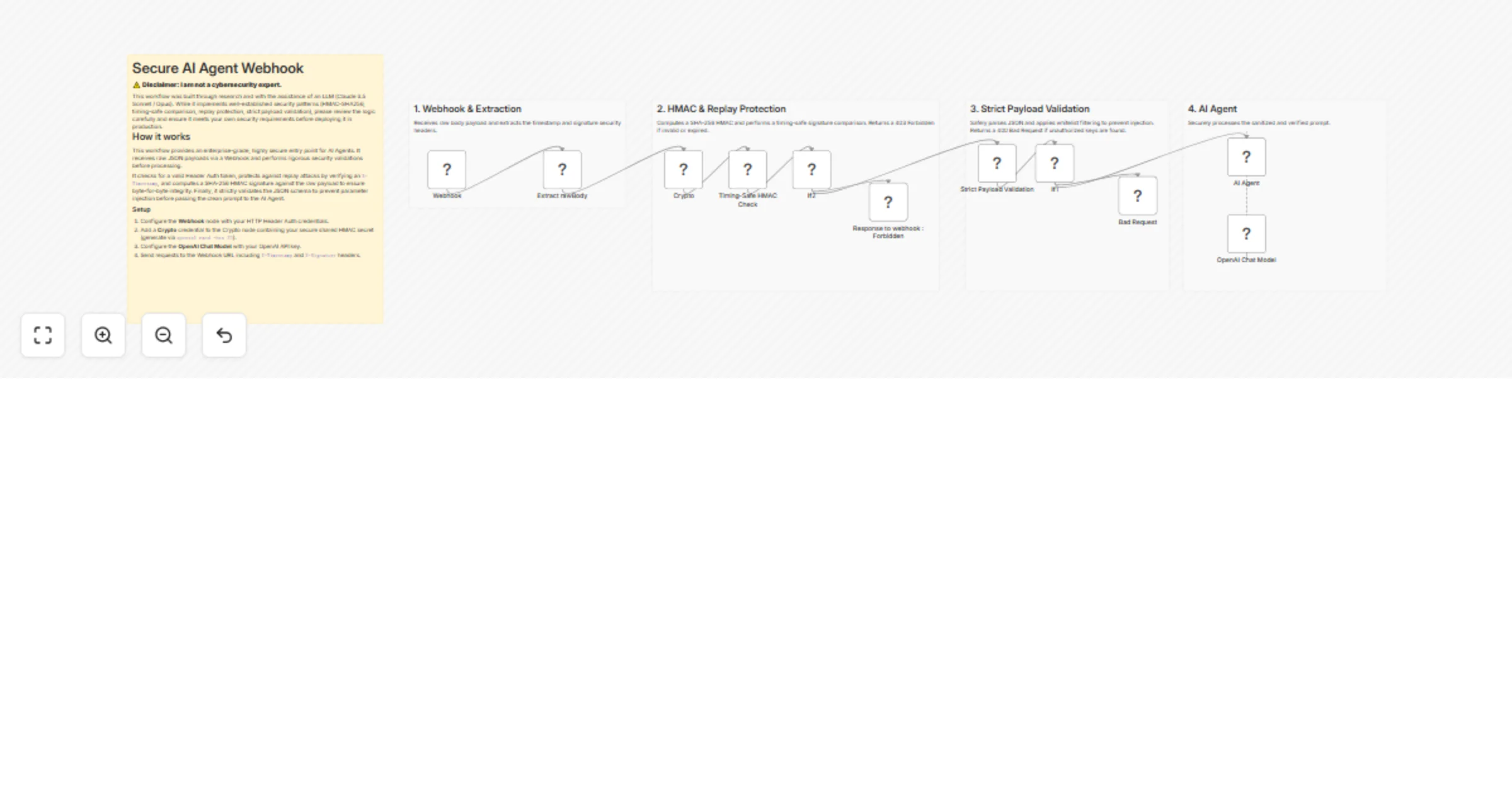
Secure AI agent webhook with HMAC, replay protection, and OpenAI GPT-5
⚠️ Disclaimer: > I am not a cybersecurity expert . This workflow was built through research and with the assistanc...

Answer questions about documentation with BigQuery RAG and OpenAI
BigQuery RAG with OpenAI Embeddings This workflow demonstrates how to use Retrieval Augmented Generation (RAG) with B...

Reliable AI agent output without structured output parser - w/ OpenAI & Switch
This workflow serves as a solid foundation when you need an AI Agent to return output in a specific JSON schema , wit...
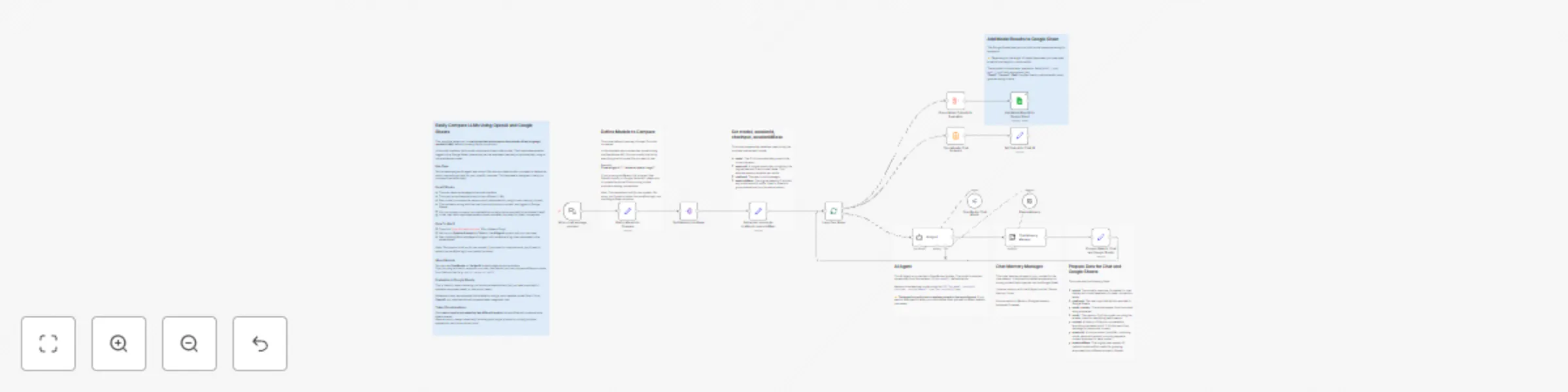
Compare different LLM responses side-by-side with Google Sheets
This workflow allows you to easily evaluate and compare the outputs of two language models (LLMs) before choosing one...
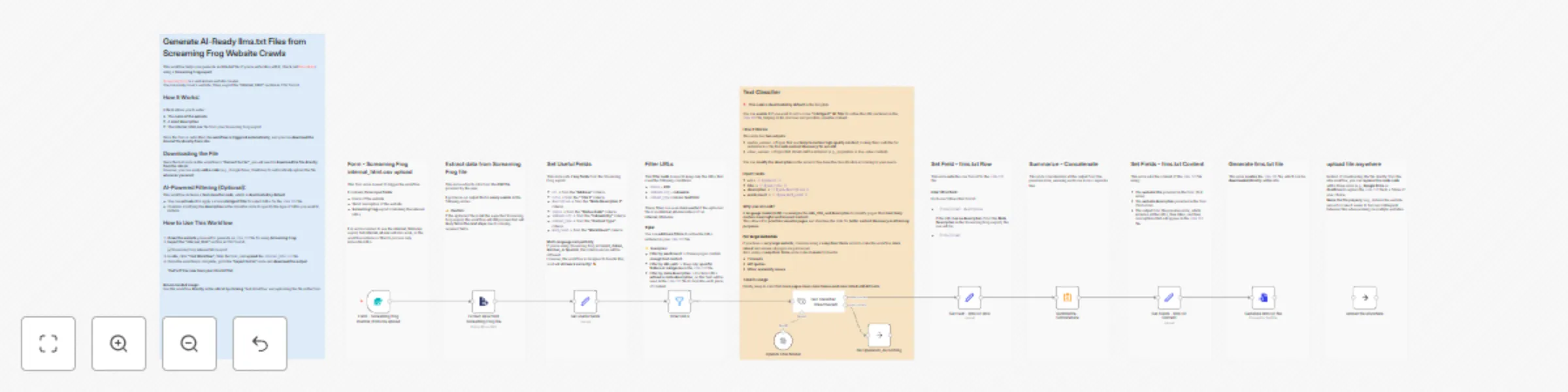
Generate AI-ready llms.txt files from Screaming Frog website crawls
This workflow helps you generate an llms.txt file (if you're unfamiliar with it, check out this article) using a Scre...

AI-generated summary block for WordPress posts
What is this workflow? This n8n template automates the process of adding an AI generated summary at the top of your W...

AI-powered information monitoring with OpenAI, Google Sheets, Jina AI and Slack
Check Legal Regulations : This workflow involves scraping, so ensure you comply with the legal regulations in your co...

AI agent : Google calendar assistant using OpenAI
This template is a simple AI Agent that acts as a Google Calendar Assistant . It is designed for beginners to have th...
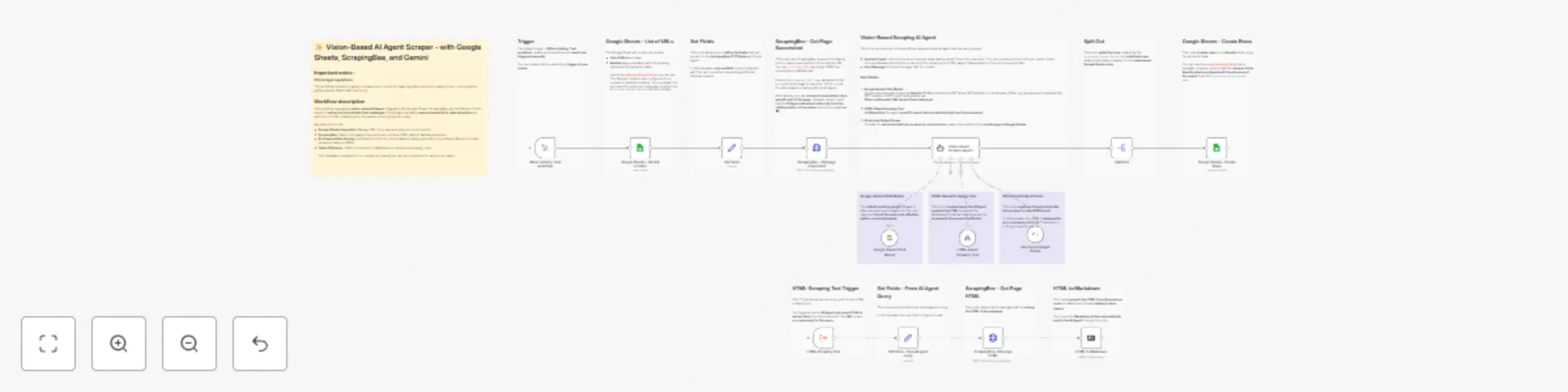
✨ Vision-based AI agent scraper - with Google Sheets, ScrapingBee, and Gemini
Important Notes: Check Legal Regulations: This workflow involves scraping, so ensure you comply with the legal regula...

AI agent to chat with you Search Console data, using OpenAI and Postgres
Edit 19/11/2024 : As explained on the workflow, the AI Agent with the original system prompt was not effective when u...

WordPress - AI chatbot to enhance user experience - with Supabase and OpenAI
This is the first version of a template for a RAG/GenAI App using WordPress content . As creating, sharing, and impro...
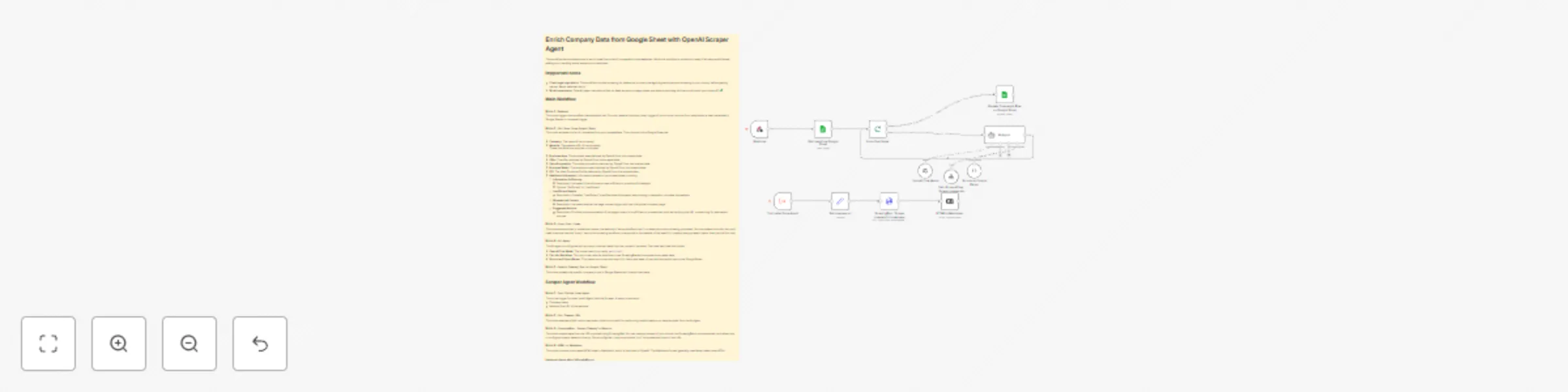
Enrich company data from Google Sheet with OpenAI Agent and ScrapingBee
This workflow demonstrates how to enrich data from a list of companies in a spreadsheet. While this workflow is produ...

Enrich Pipedrive's Organization Data with OpenAI GPT-4o & Notify it in Slack
This workflow enriches new Pipedrive organization's data by adding a note to the organization object in Pipedrive . I...
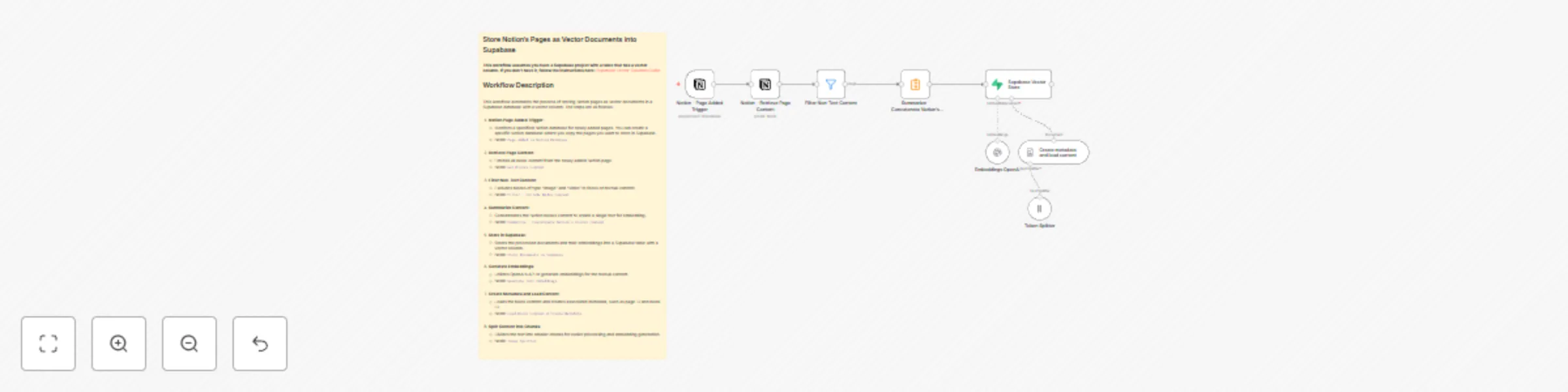
Store Notion's Pages as Vector Documents into Supabase with OpenAI
Workflow updated on 17/06/2024: Added 'Summarize' node to avoid creating a row for each Notion content block in the S...