Evaluations metric: answer similarity
Workflow preview
$20/month : Unlimited workflows
2500 executions/month
THE #1 IN WEB SCRAPING
Scrape any website without limits
HOSTINGER  Early Deal
Early Deal
DISCOUNT 20% Try free
DISCOUNT 20%
Self-hosted n8n
Unlimited workflows - from $4.99/mo
#1 hub for scraping, AI & automation
6000+ actors - $5 credits/mo
Important notice
This workflow is provided as-is. Please review and test before using in production.
Overview
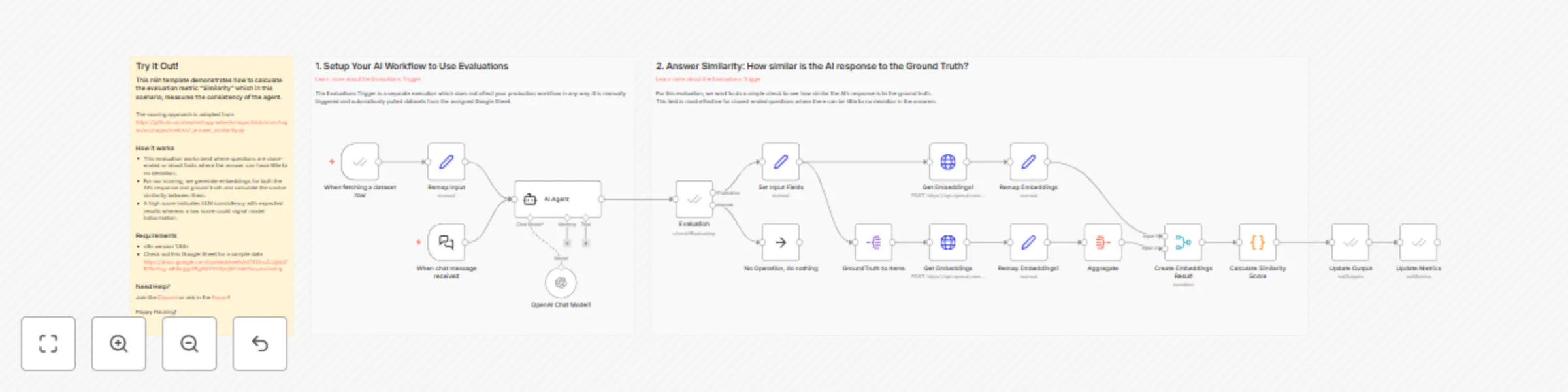
This n8n template demonstrates how to calculate the evaluation metric "Similarity" which in this scenario, measures the consistency of the agent.
The scoring approach is adapted from the open-source evaluations project RAGAS and you can see the source here https://github.com/explodinggradients/ragas/blob/main/ragas/src/ragas/metrics/_answer_similarity.py
How it works
- This evaluation works best where questions are close-ended or about facts where the answer can have little to no deviation.
- For our scoring, we generate embeddings for both the AI's response and ground truth and calculate the cosine similarity between them.
- A high score indicates LLM consistency with expected results whereas a low score could signal model hallucination.
Requirements
- n8n version 1.94+
- Check out this Google Sheet for a sample data https://docs.google.com/spreadsheets/d/1YOnu2JJjlxd787AuYcg-wKbkjyjyZFgASYVV0jsij5Y/edit?usp=sharing