Scrape and ingest web content into Supabase pgvector with Firecrawl
Workflow preview
$20/month : Unlimited workflows
2500 executions/month
THE #1 IN WEB SCRAPING
Scrape any website without limits
HOSTINGER  Early Deal
Early Deal
DISCOUNT 20% Try free
DISCOUNT 20%
Self-hosted n8n
Unlimited workflows - from $4.99/mo
#1 hub for scraping, AI & automation
6000+ actors - $5 credits/mo
Overview
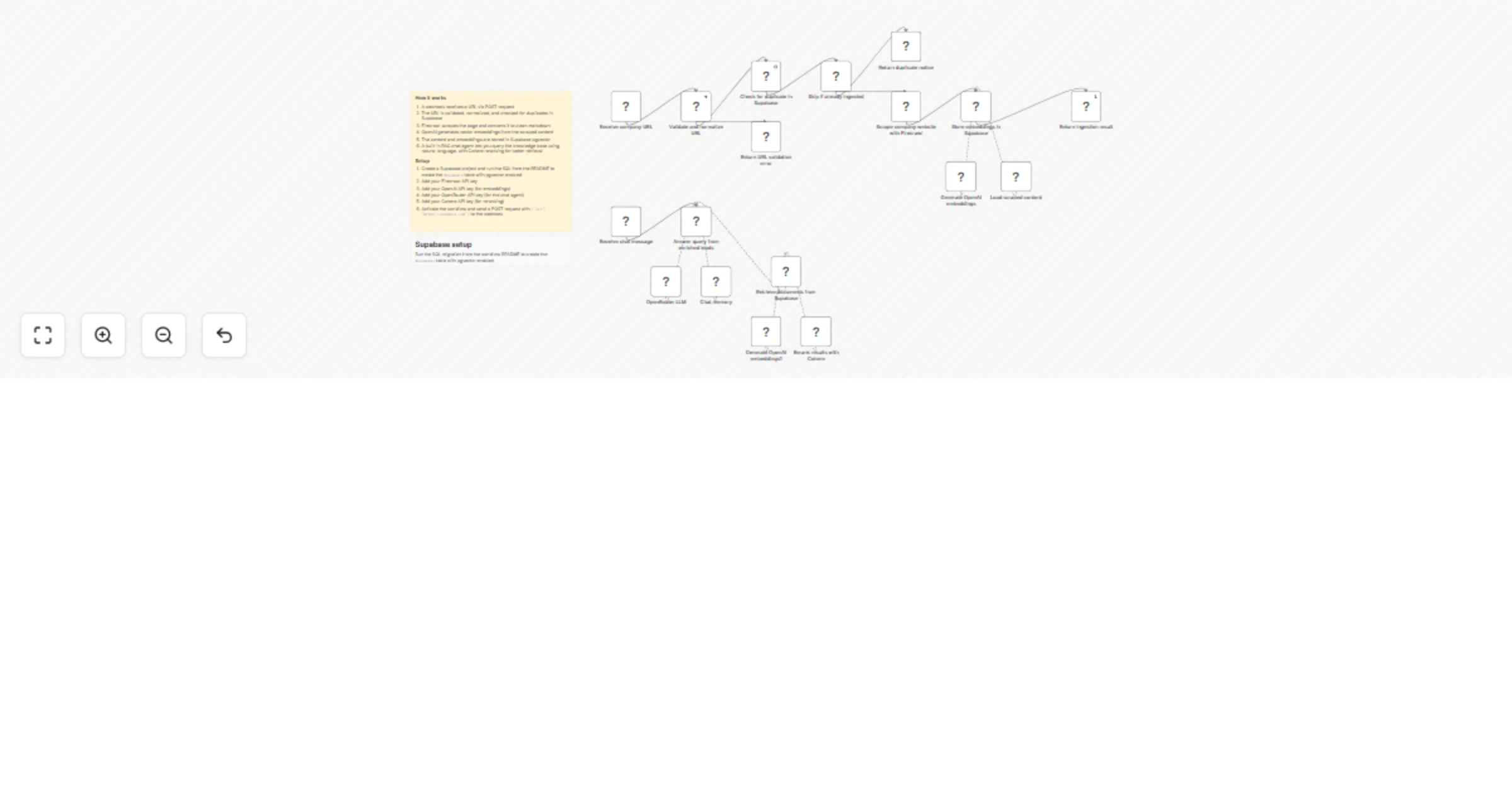
What this does
Receives a URL via webhook, uses Firecrawl to scrape the page into clean markdown, and stores it as vector embeddings in Supabase pgvector. A visual, self-hosted ingestion pipeline for RAG knowledge bases. Adding a new source is as simple as sending a URL.
The second part of the workflow exposes a chat interface where an AI Agent queries the stored knowledge base to answer questions, with Cohere reranking for better retrieval quality.
How it works
Part 1: Ingestion Pipeline
- Webhook receives a POST request with a
urlfield - Verify URL validates and normalizes the domain
- Supabase checks if the URL was already ingested (deduplication)
- If the URL already exists, ingestion is skipped; otherwise it continues
- Firecrawl fetches the page and converts it to clean markdown
- OpenAI generates vector embeddings from the scraped content
- Default Data Loader attaches the source URL as metadata
- Supabase Vector Store inserts the content and embeddings into pgvector
- Respond to Webhook confirms how many items were added
Part 2: RAG Chat Agent
- Chat trigger receives a user question
- AI Agent (OpenRouter) queries the Supabase vector store filtered by URL
- Cohere Reranker improves retrieval quality before the agent responds
- Agent answers based solely on the ingested knowledge base
Requirements
- Firecrawl API key
- OpenAI API key (for embeddings)
- OpenRouter API key (for the chat agent)
- Cohere API key (for reranking)
- Supabase project with pgvector enabled
Setup
- Create a Supabase project and run the following SQL in the SQL editor:
-- Enable the pgvector extension
create extension vector
with
schema extensions;
-- Create a table to store documents
create table documents (
id bigserial primary key,
content text,
metadata jsonb,
embedding extensions.vector(1536)
);
-- Create a function to search for documents
create function match_documents (
query_embedding extensions.vector(1536),
match_count int default null,
filter jsonb default '{}'
) returns table (
id bigint,
content text,
metadata jsonb,
similarity float
)
language plpgsql
as $$
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where metadata @> filter
order by documents.embedding <=> query_embedding
limit match_count;
end;
$$;
- Add your Firecrawl API key as a credential in n8n
- Add your OpenAI API key as a credential (for embeddings)
- Add your OpenRouter API key as a credential (for the chat agent)
- Add your Cohere API key as a credential (for reranking)
- Activate the workflow
How to use
Send a POST request to the webhook URL:
curl -X POST https://your-n8n-instance/webhook/your-id \
-H "Content-Type: application/json" \
-d '{"url": "https://firecrawl.dev/docs"}'
Then open the chat interface in n8n to ask questions about the ingested content.