Extract personal data with self-hosted LLM Mistral NeMo
Workflow preview
$20/month : Unlimited workflows
2500 executions/month
THE #1 IN WEB SCRAPING
Scrape any website without limits
HOSTINGER  Early Deal
Early Deal
DISCOUNT 20% Try free
DISCOUNT 20%
Self-hosted n8n
Unlimited workflows - from $4.99/mo
#1 hub for scraping, AI & automation
6000+ actors - $5 credits/mo
Important notice
This workflow is provided as-is. Please review and test before using in production.
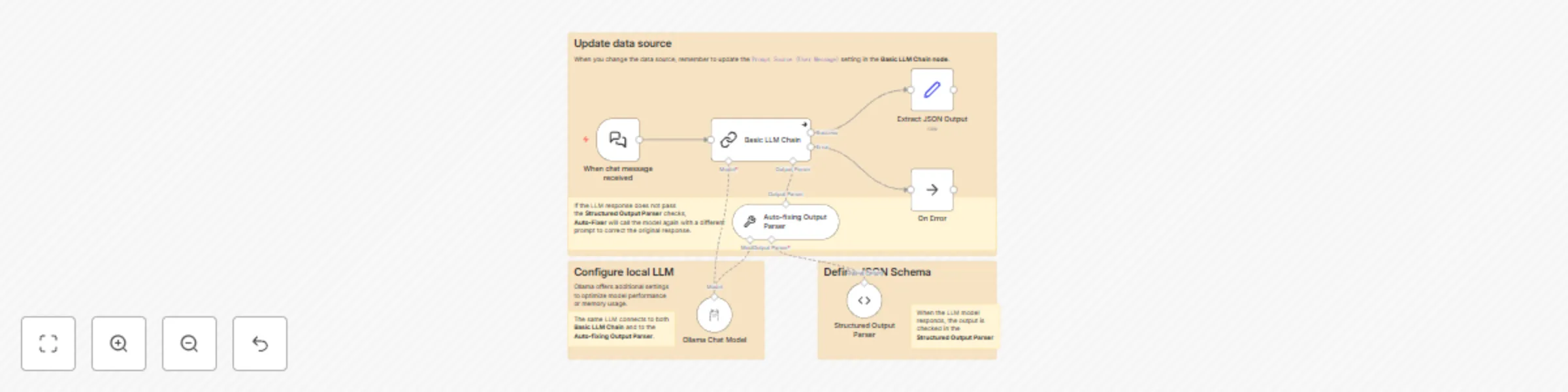
Overview
This workflow shows how to use a self-hosted Large Language Model (LLM) with n8n's LangChain integration to extract personal information from user input. This is particularly useful for enterprise environments where data privacy is crucial, as it allows sensitive information to be processed locally.
📖 For a detailed explanation and more insights on using open-source LLMs with n8n, take a look at our comprehensive guide on open-source LLMs.
🔑 Key Features
Local LLM
- Connect Ollama to run Mistral NeMo LLM locally
- Provide a foundation for compliant data processing, keeping sensitive information on-premises
Data extraction
- Convert unstructured text to a consistent JSON format
- Adjust the JSON schema to meet your specific data extraction needs.
Error handling
- Implement auto-fixing for LLM outputs
- Include error output for further processing
⚙️ Setup and сonfiguration
Prerequisites
- n8n AI Starter Kit installed
Configuration steps
- Add the Basic LLM Chain node with system prompts.
- Set up the Ollama Chat Model with optimized parameters.
- Define the JSON schema in the Structured Output Parser node.
🔍 Further resources
Apply the power of self-hosted LLMs in your n8n workflows while maintaining control over your data processing pipeline!