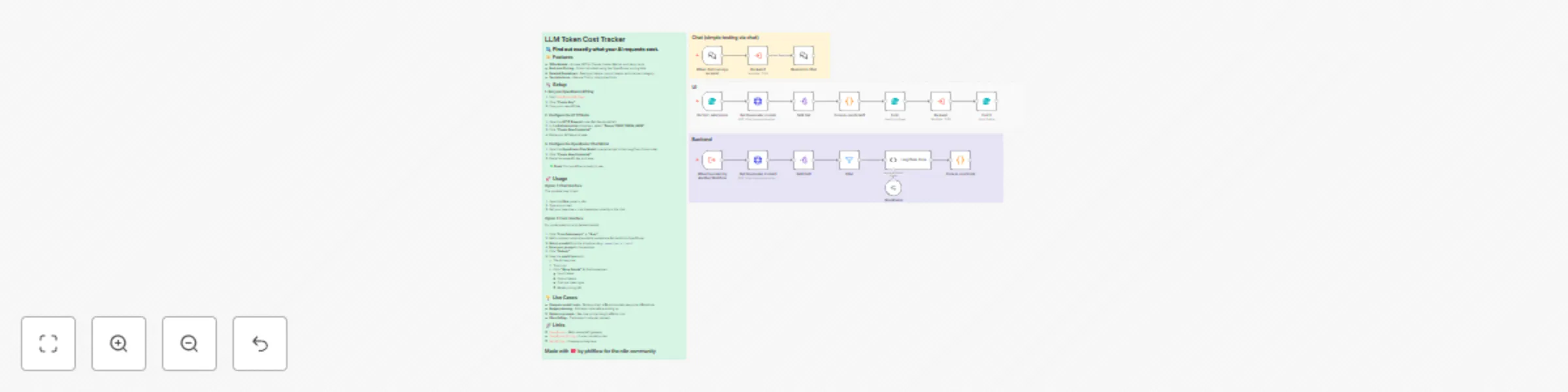
This n8n template lets you run prompts against 350+ LLM models and see exactly what each request costs with real time...