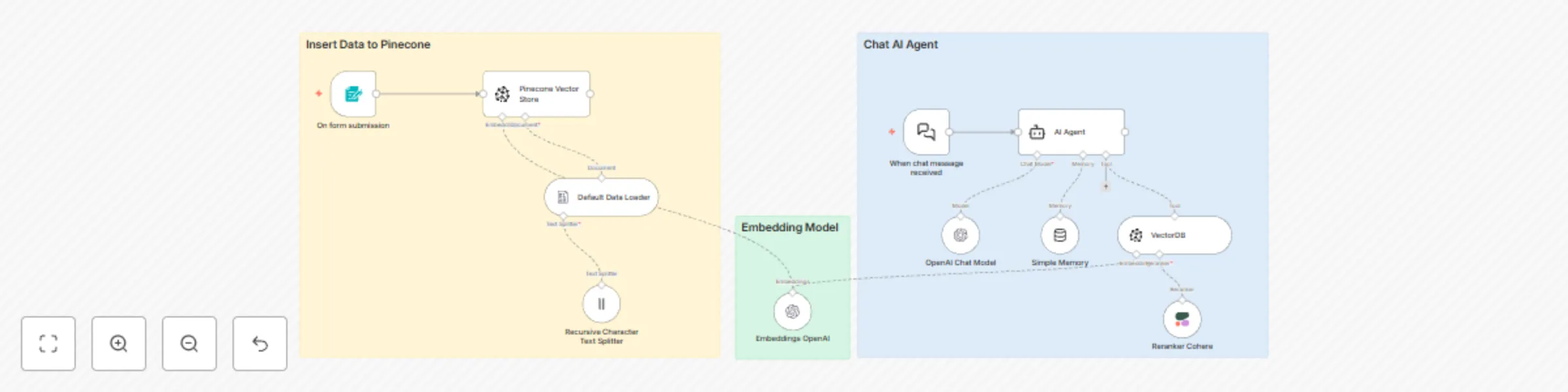
This workflow contains community nodes that are only compatible with the self hosted version of n8n. This workflow pr...