Jimleuk
Workflows by Jimleuk
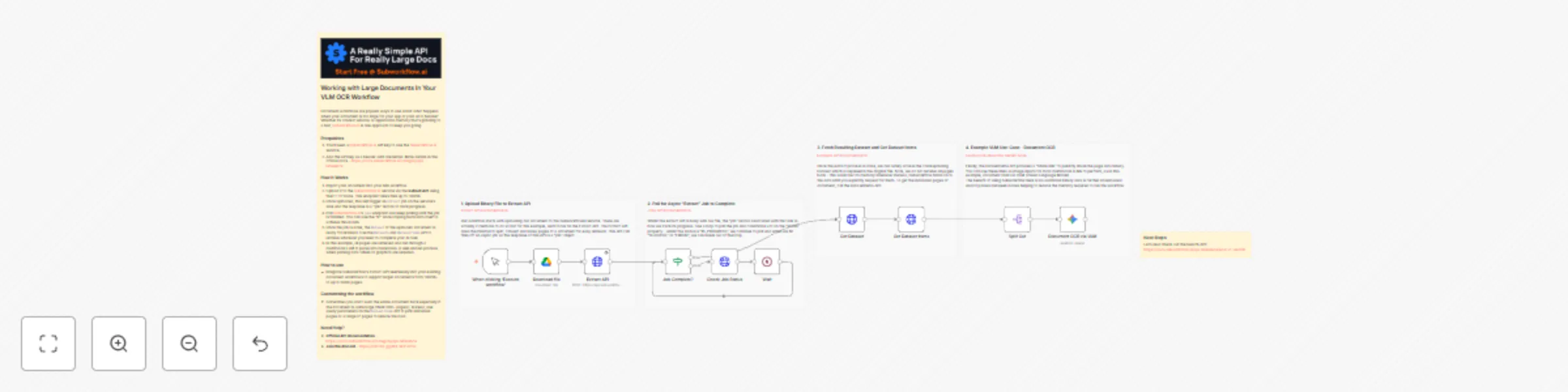
Process large documents with OCR using SubworkflowAI and Gemini
Working with Large Documents In Your VLM OCR Workflow Document workflows are popular ways to use AI but what happens...
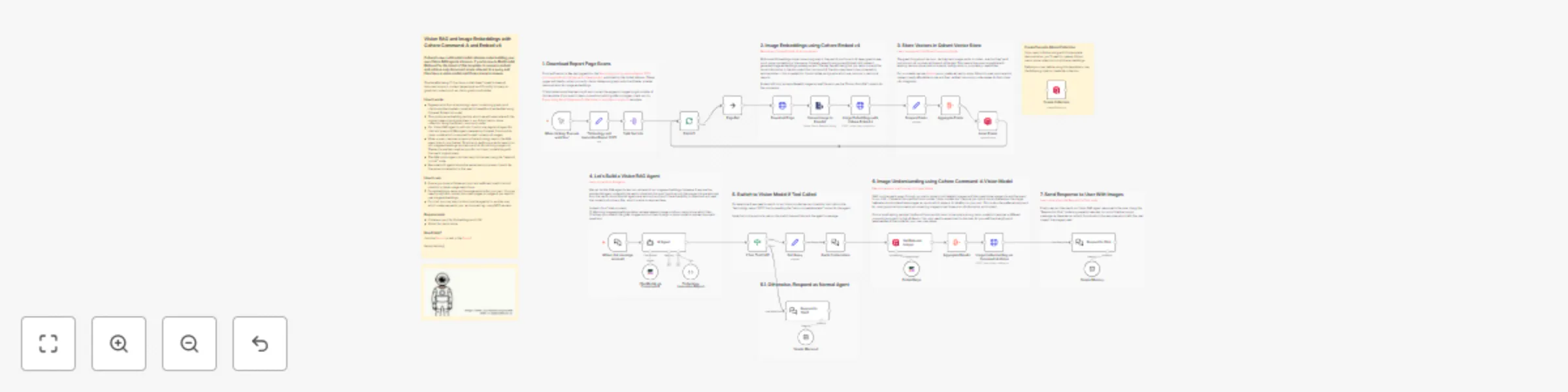
Vision RAG and image embeddings using Cohere Command-A and Embed v4
Cohere's new multimodal model releases make building your own Vision RAG agents a breeze. If you're new to Multimodal...
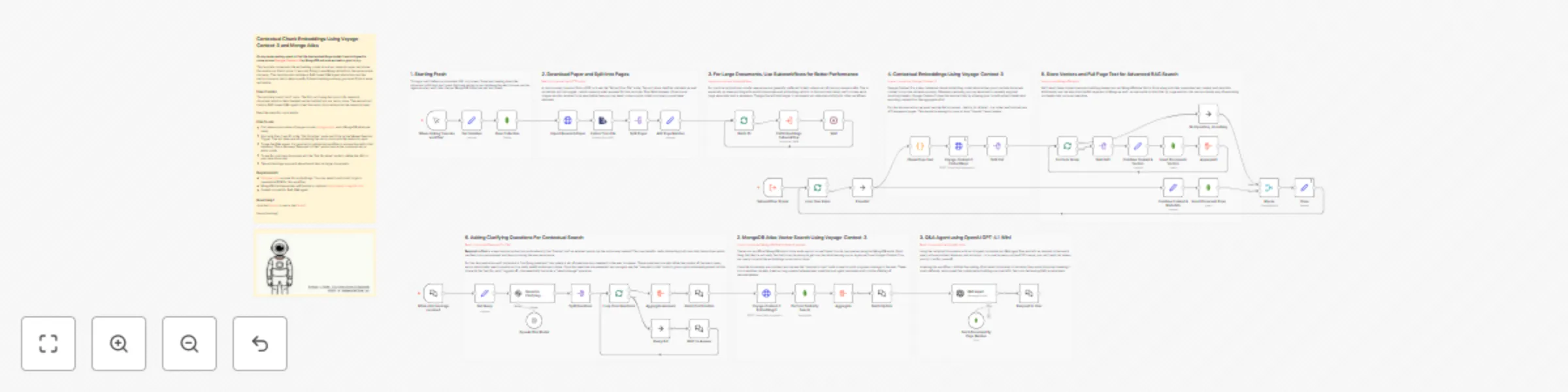
Document Q&A system with Voyage-Context-3 embeddings and MongoDB Atlas
On my never ending quest to find the best embeddings model, I was intrigued to come across Voyage Context 3 by MongoD...
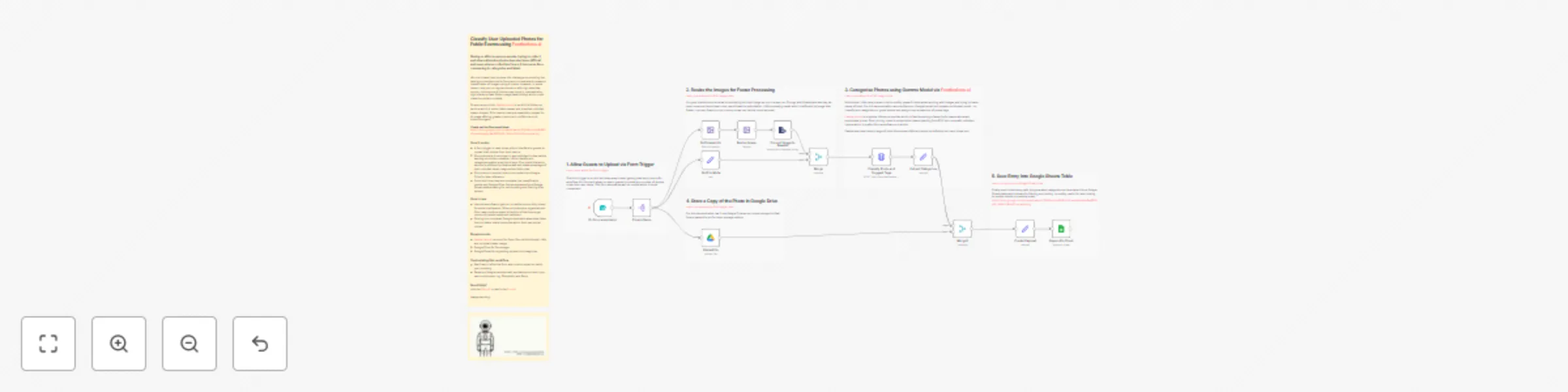
Classify event photos from attendees with Gemma AI, Google Drive & Sheets
There's a clear need for an easier way to manage attendee photos from live events, as current processes for collectin...

Build document RAG system with Kimi-K2, Gemini embeddings and Qdrant
Generating contextual summaries is an token int...

Monitor file changes with Google Drive push notifications
Tired of being let down by the Google Drive Trigger? Rather not exhaust system resources by polling every minute? The...
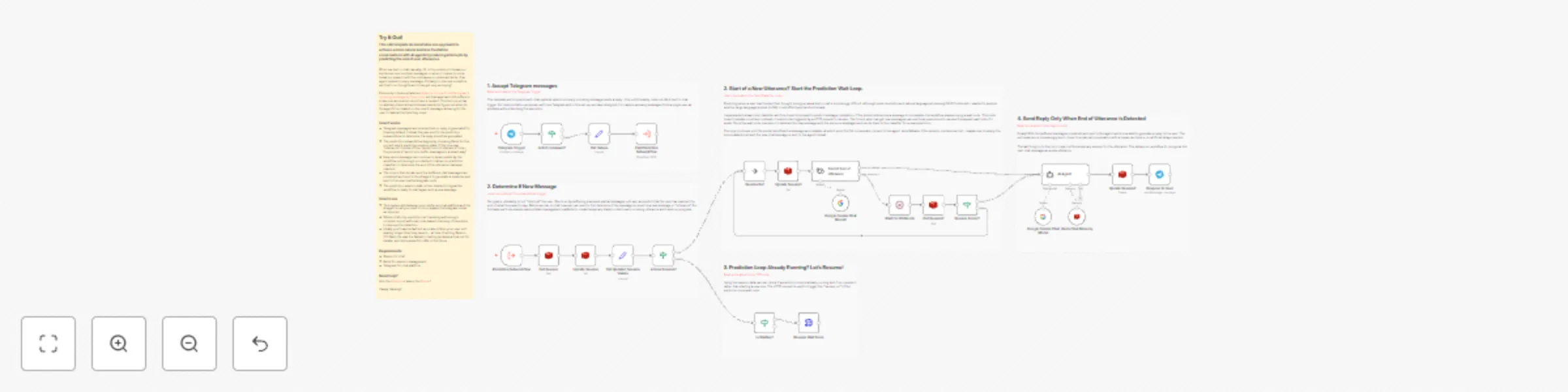
End of turn detection for smoother AI agent chats with Telegram and Gemini
This n8n template demonstrates one approach to achieve a more natural and less frustration conversations with AI agen...

Track n8n workflow changes over time with compare dataset & Google Sheets
This n8n template runs daily to track and report on any changes made to workflows on any n8n instance. Useful if a te...

Compose/Stitch separate images together using n8n & Gemini AI image editing
This n8n template demonstrates how to use AI to compose or "stitch" separate images together to generate a new image...
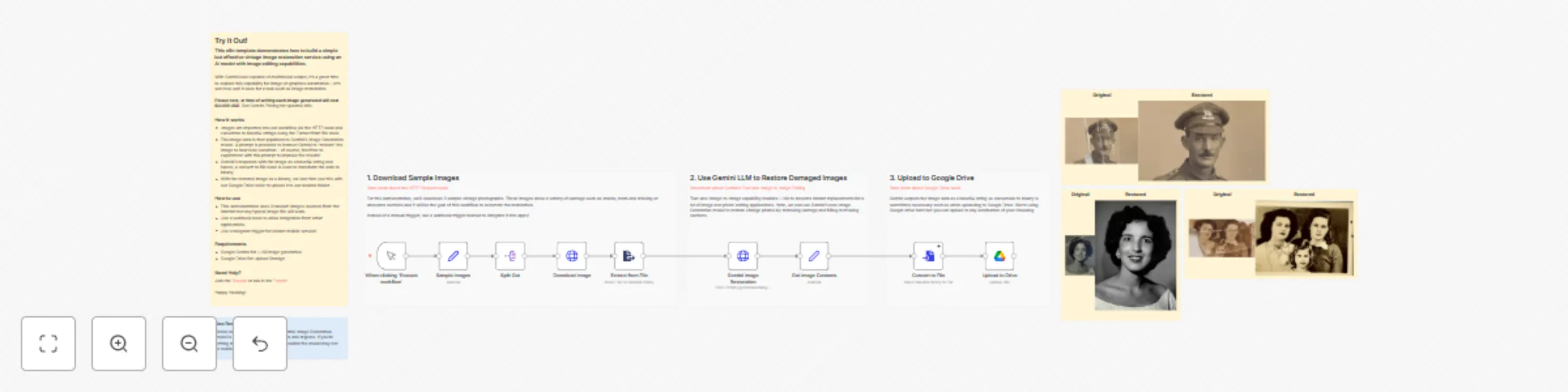
Build an image restoration service with n8n & Gemini AI image editing
This n8n template demonstrates how to build a simple but effective vintage image restoration service using an AI mode...
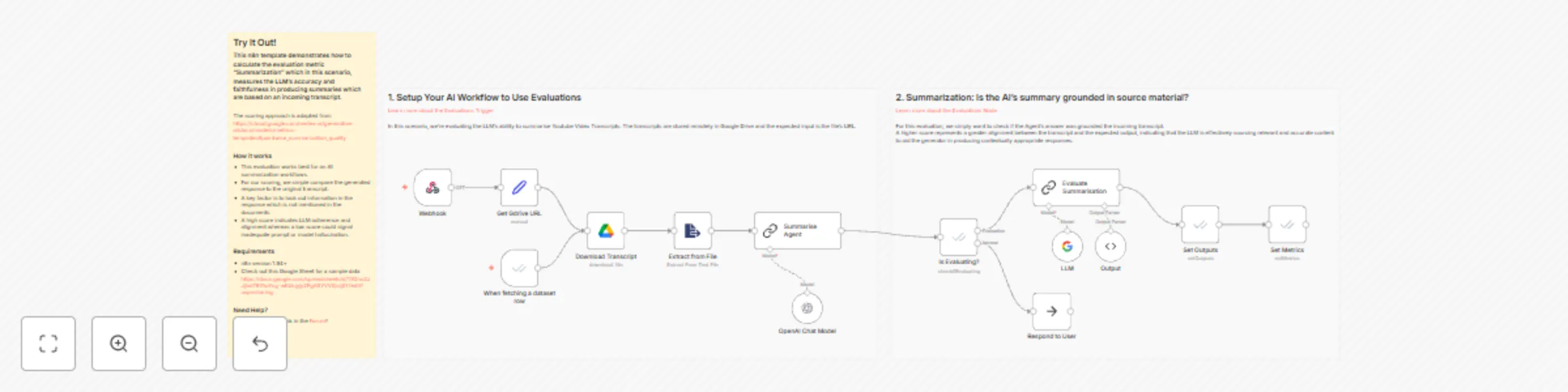
Evaluation metric: summarization
This n8n template demonstrates how to calculate the evaluation metric "Summarization" which in this scenario, measure...

Evaluate RAG response accuracy with OpenAI: document groundedness metric
This n8n template demonstrates how to calculate the evaluation metric "RAG document groundedness" which in this scena...
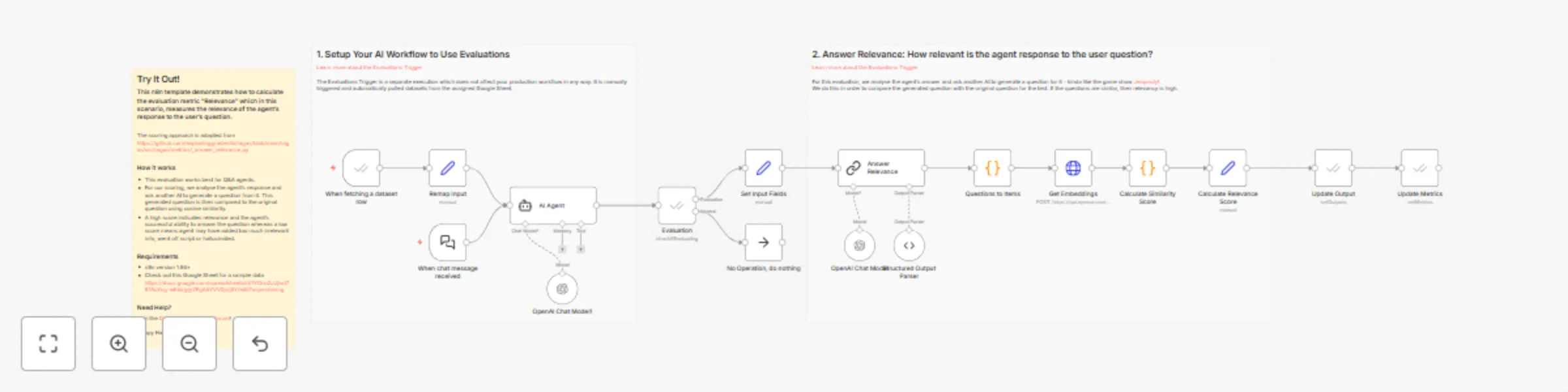
Evaluate AI agent response relevance using OpenAI and cosine similarity
This n8n template demonstrates how to calculate the evaluation metric "Relevance" which in this scenario, measures th...
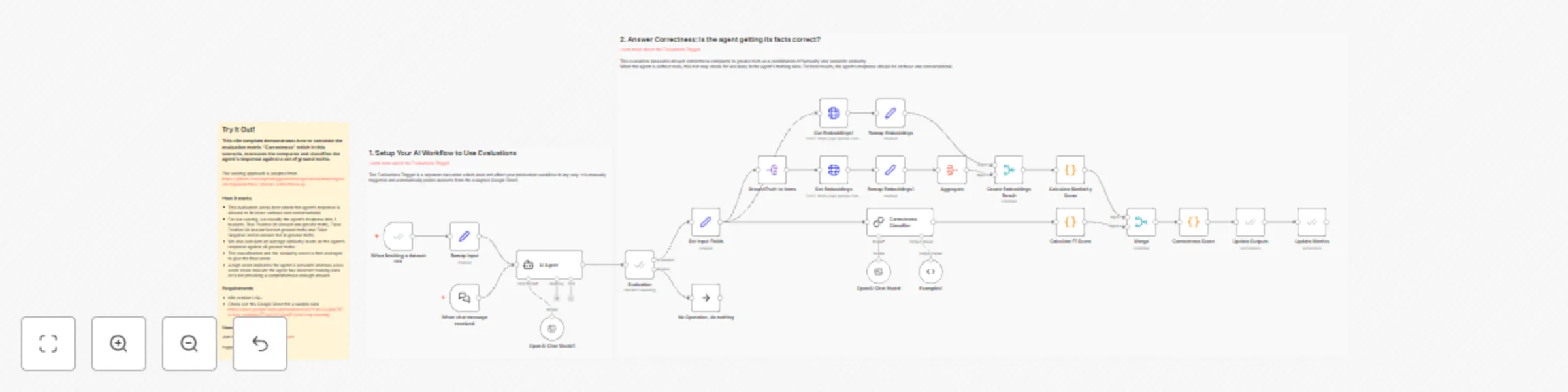
Evaluate AI agent response correctness with OpenAI and RAGAS methodology
This n8n template demonstrates how to calculate the evaluation metric "Correctness" which in this scenario, measures...
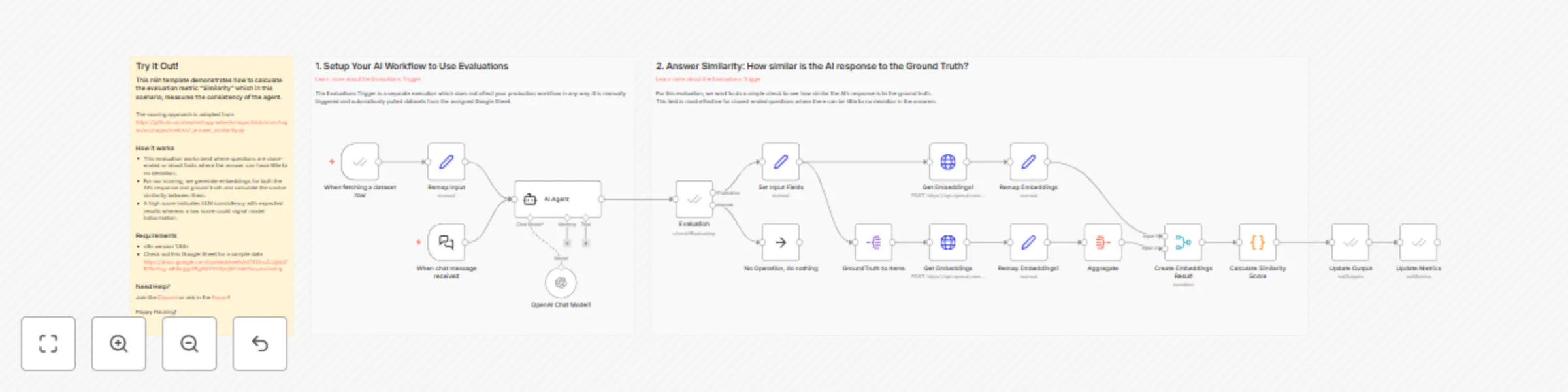
Evaluations metric: answer similarity
This n8n template demonstrates how to calculate the evaluation metric "Similarity" which in this scenario, measures t...

Validate Auth0 JWT tokens using JWKS or signing cert
> Note: This template requires a self hosted community edition of n8n. Does not work on cloud. Try It Out This n8n...

OpenAI responses API adapter for LLM and AI agent workflows
This n8n template demonstrates how to use OpenAI's Responses API with existing LLM and AI Agent nodes. Though I would...

Create OpenAI-compatible API using GitHub models for free AI access
This n8n template shows you how to connect Github's Free Models to your existing n8n AI workflows. Whilst it is possi...
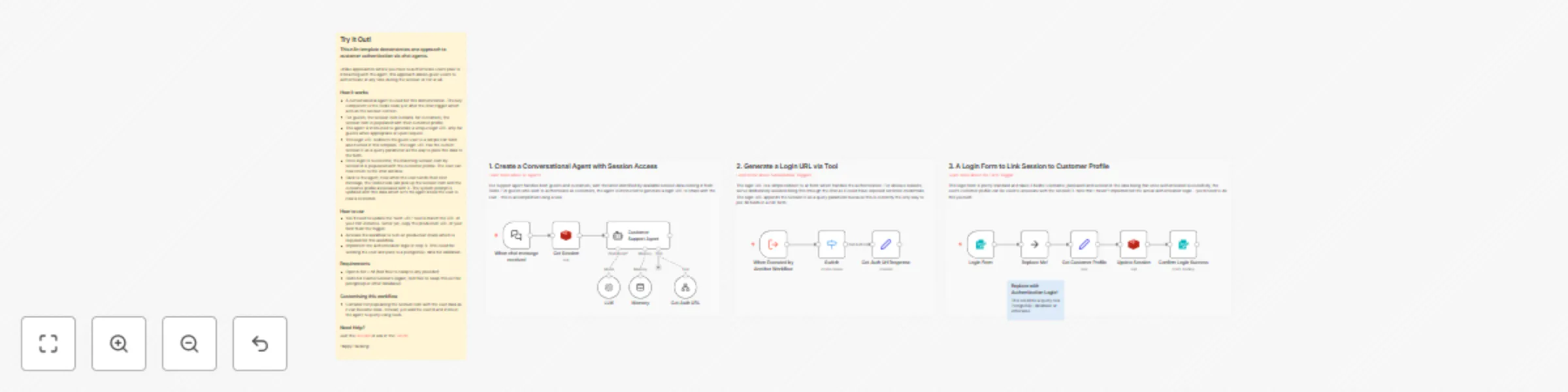
Customer authentication for chat support with OpenAI and Redis session management
This n8n template demonstrates one approach to customer authentication via chat agents. Unlike approaches where you h...

Summarise MS Teams channel activity for weekly reports with AI
This n8n template lets you summarize individual team member activity on MS Teams for the past week and generates a re...
Summarise Slack channel activity for weekly reports with AI
This n8n template lets you summarize team member activity on Slack for the past week and generates a report. For remo...
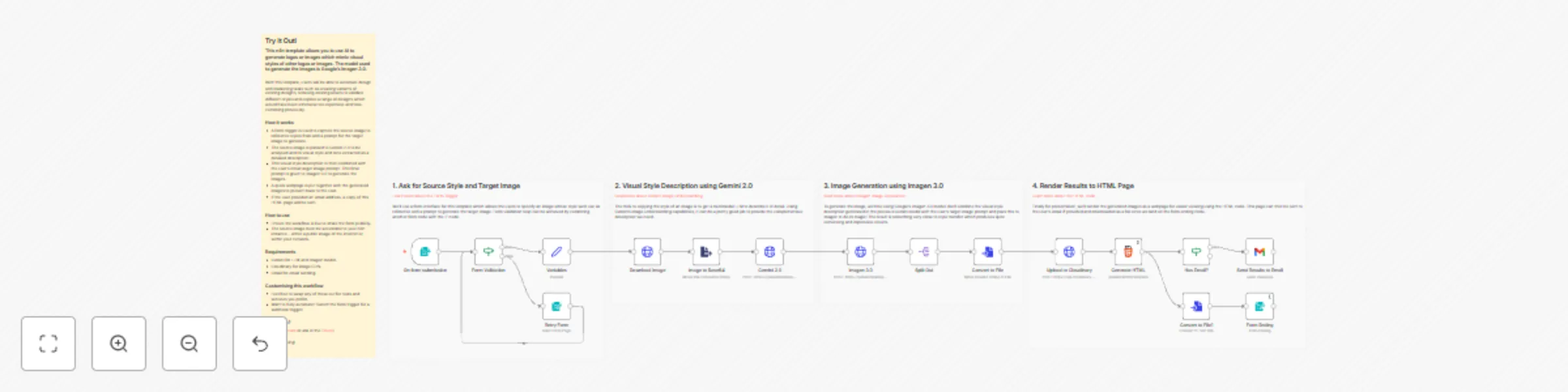
Generate logos and images with consistent visual styles using Imagen 3.0
This n8n template allows you to use AI to generate logos or images which mimic visual styles of other logos or images...
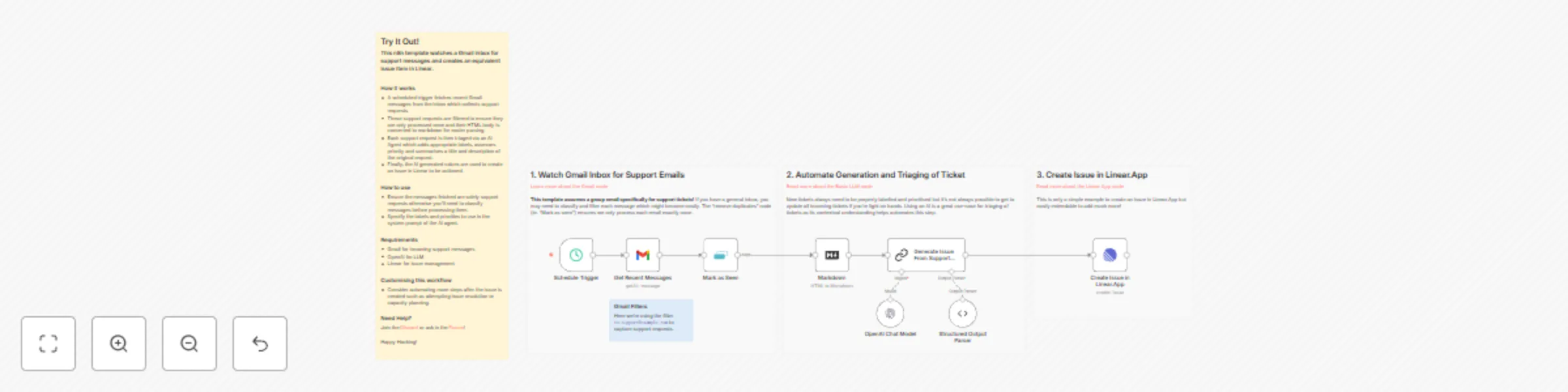
Automatically create Linear issues from Gmail support request messages
This n8n template watches a Gmail inbox for support messages and creates an equivalent issue item in Linear. How it w...
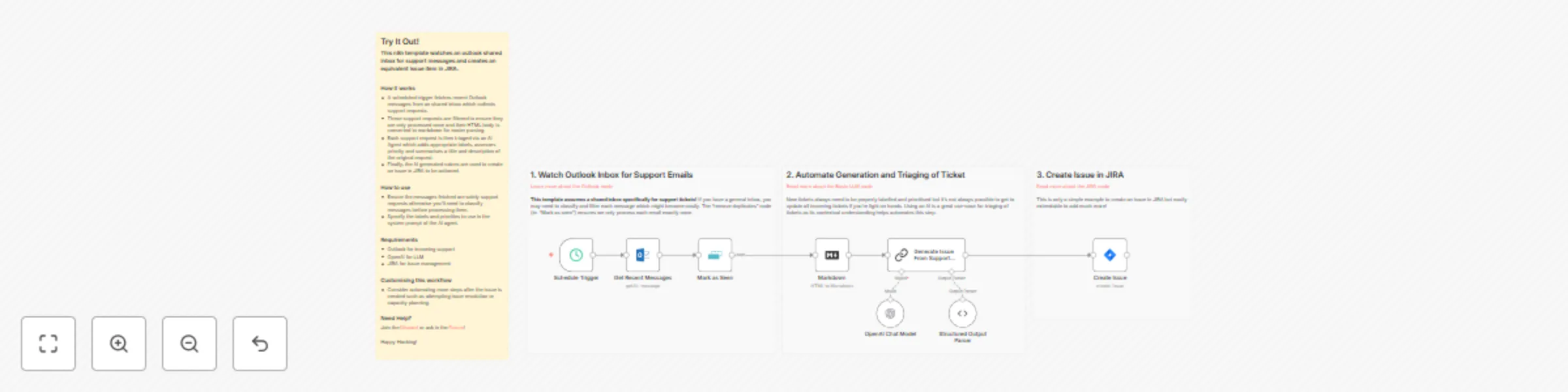
Automatically create JIRA issues from Outlook email support requests
This n8n template watches an outlook shared inbox for support messages and creates an equivalent issue item in JIRA....