C
Cheney Zhang
3
Workflows
Workflows by Cheney Zhang
Free advanced
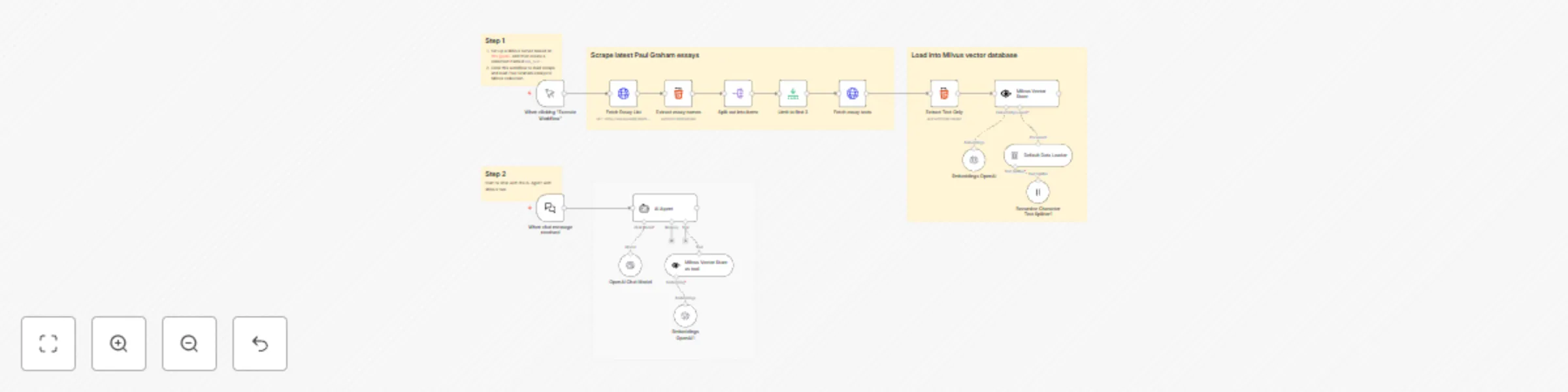
Paul Graham essay search & chat with Milvus vector database
Paul Graham Essay Search & Chat with Milvus Vector Database How It Works This workflow creates a RAG (Retrieval Augme...
C
Cheney Zhang Engineering
16 Apr 2025
1425
0

Free advanced
Create a Paul Graham essay Q&A system with OpenAI and Milvus vector database
Create a Paul Graham Essay Q&A System with OpenAI and Milvus Vector Database How It Works This workflow creates a que...
C
Cheney Zhang Engineering
16 Apr 2025
1144
0

Free advanced
Create a RAG system with Paul Essays, Milvus, and OpenAI for cited answers
Create a RAG System with Paul Essays, Milvus, and OpenAI for Cited Answers This workflow automates the process of cre...
C
Cheney Zhang Internal Wiki
16 Apr 2025
2171
0