
vinci-king-01
Workflows by vinci-king-01

Back up databases and files to Box with Mailgun email notifications
Scheduled Backup Automation – Mailgun & Box This workflow automatically schedules, packages, and uploads backups of y...
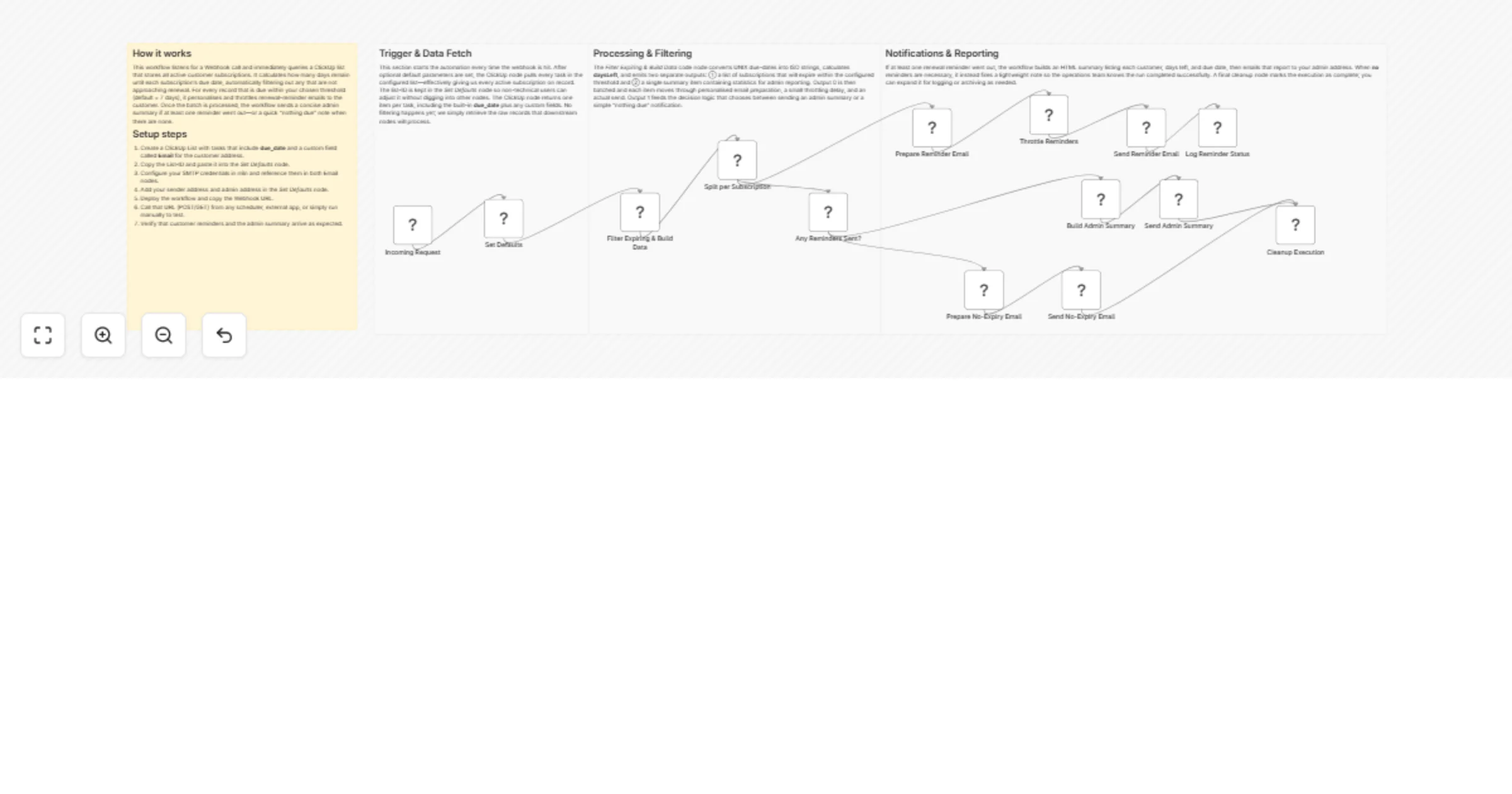
Send subscription renewal reminders with Email and ClickUp
Subscription Renewal Reminder – Email & ClickUp Automate the tracking of customer subscription expiry dates, create r...
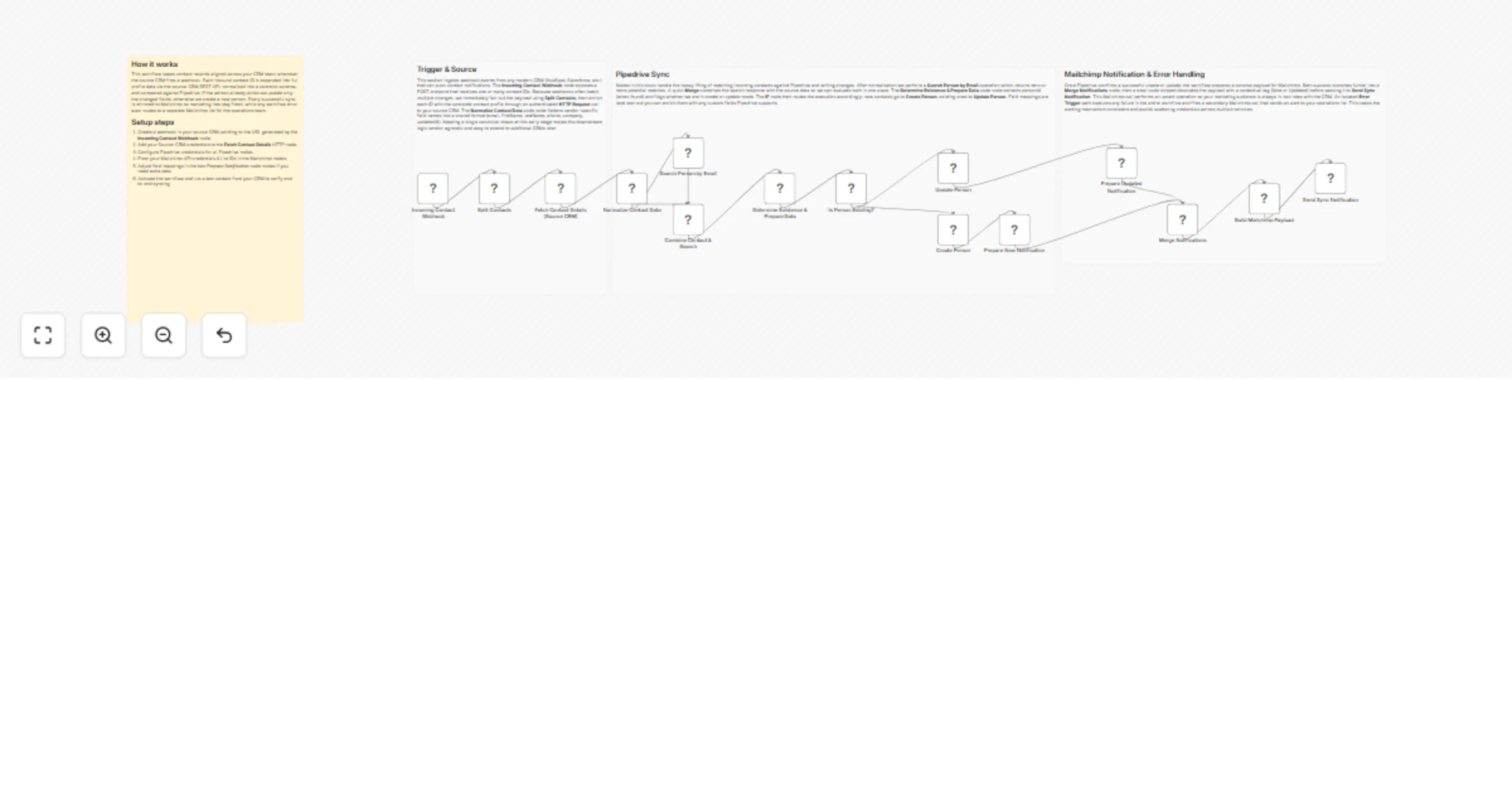
Sync CRM contacts with Mailchimp and Pipedrive
CRM Contact Sync with Mailchimp and Pipedrive This workflow keeps your contact records perfectly aligned between your...

Send subscription renewal reminders via Telegram with Supabase
Subscription Renewal Reminder – Telegram & Supabase This workflow tracks upcoming subscription expiry dates stored in...

Process incoming files and notify via email with GitHub storage
File Processing Pipeline with Email and GitHub This workflow automatically ingests newly uploaded files, validates an...

Score and route qualified leads to Notion and Matrix
Lead Scoring Pipeline – Matrix + Notion This workflow automatically enriches incoming form leads, applies a customiza...
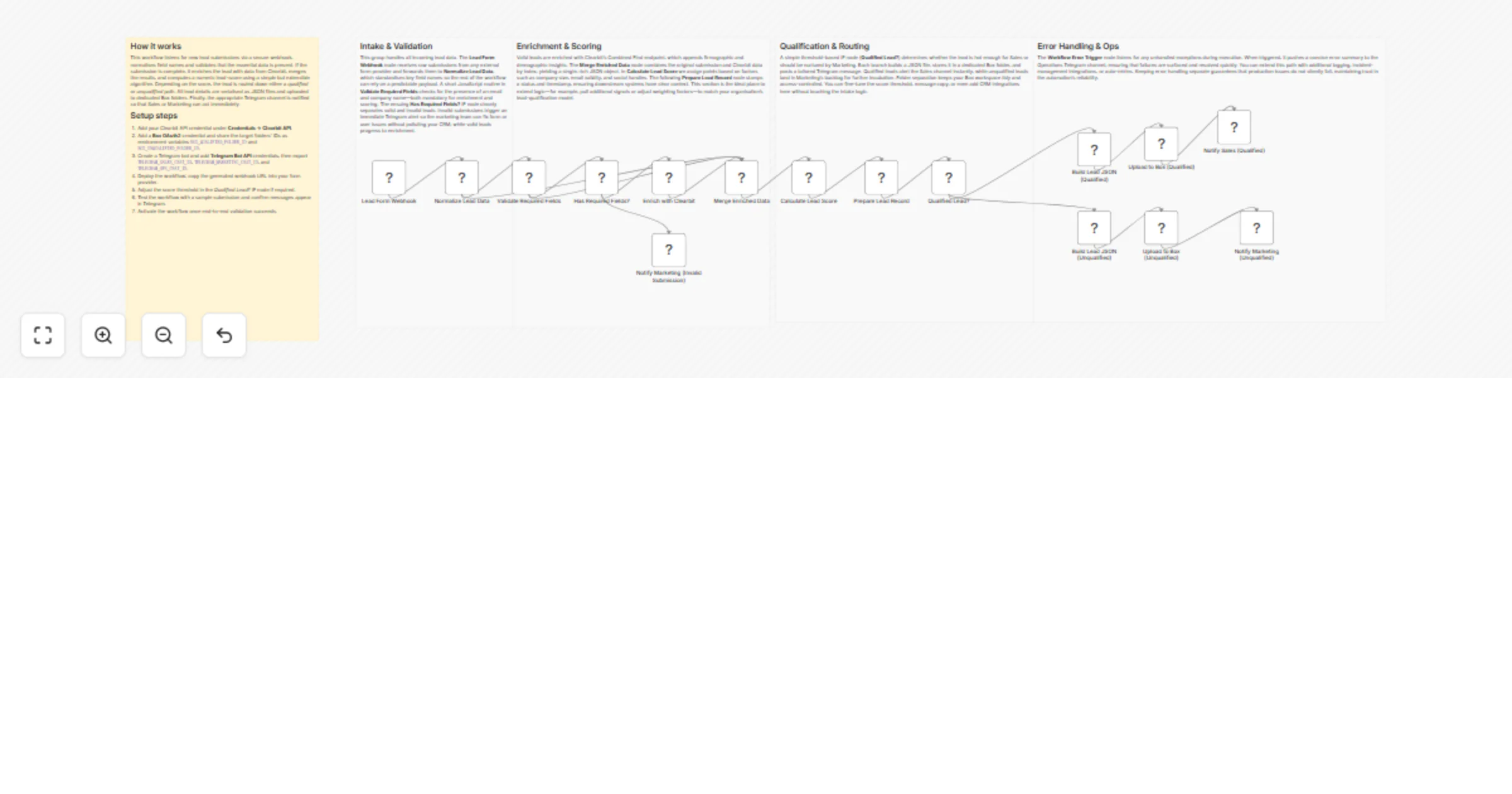
Score and route leads with Telegram alerts and Box storage
Lead Scoring Pipeline with Telegram and Box This workflow ingests incoming lead data from a form submission webhook,...

Aggregate error alerts and send consolidated reports via Email and Jira
Error Alert Aggregator – Email and Jira This workflow aggregates error logs arriving from multiple sources, deduplica...

Handle approval requests with SendGrid email and Baserow records
Approval Workflow Handler – SendGrid & Baserow This workflow automates the end to end approval process for any reques...
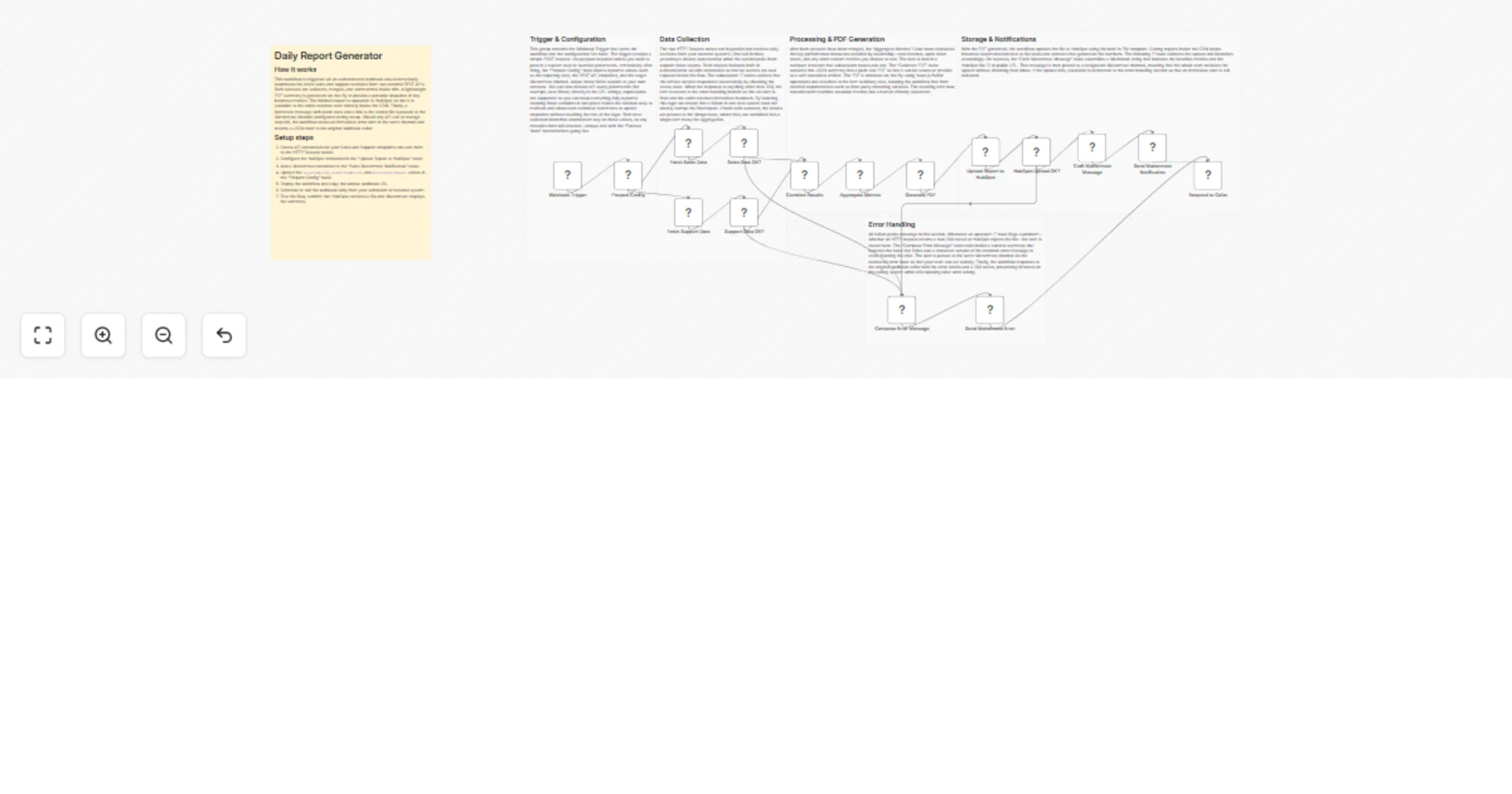
Send daily CRM summary reports to Mattermost from HubSpot
Daily Report Generator with Mattermost and HubSpot This workflow automatically compiles key metrics from HubSpot (and...

Send meeting summaries with Mailchimp and MongoDB
Meeting Notes Distributor – Mailchimp and MongoDB This workflow automatically converts raw meeting recordings or writ...

Score and route leads with Clearbit, Mattermost and Trello
Lead Scoring Pipeline with Mattermost and Trello This workflow automatically enriches incoming form based leads, calc...

Distribute summarized meeting notes with Microsoft Teams and ClickUp
This workflow processes raw meeting recordings or handwritten notes, automatically transcribes and summarizes them, a...

Sync your HRIS employee directory with Microsoft Teams, Coda, and Slack
Employee Directory Sync – Microsoft Teams & Coda ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community contributed te...
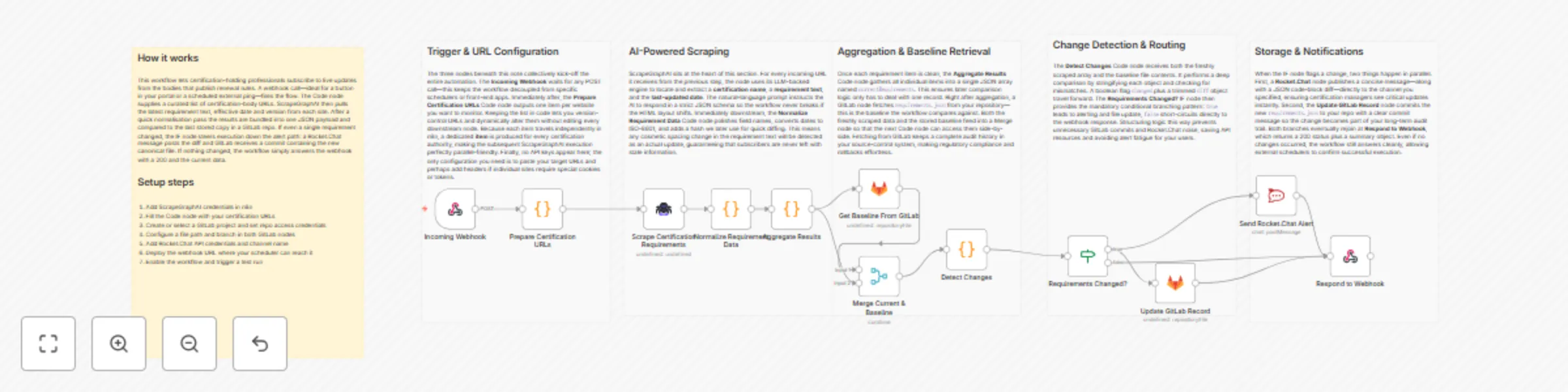
Track certification requirements with ScrapeGraphAI, GitLab and Rocket.Chat
Certification Requirement Tracker with Rocket.Chat and GitLab ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community c...

Aggregate commercial property listings with ScrapeGraphAI, Baserow and Teams
Property Listing Aggregator with Microsoft Teams and Baserow ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community co...
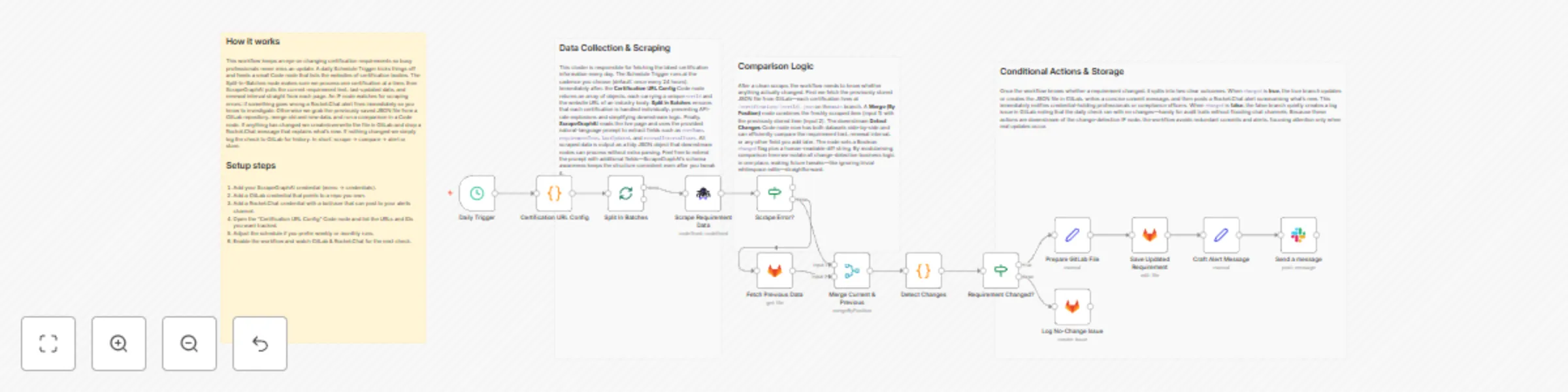
Automatically track certification changes with ScrapeGraphAI, GitLab and Rocket.Chat
Certification Requirement Tracker with Rocket.Chat and GitLab ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community c...
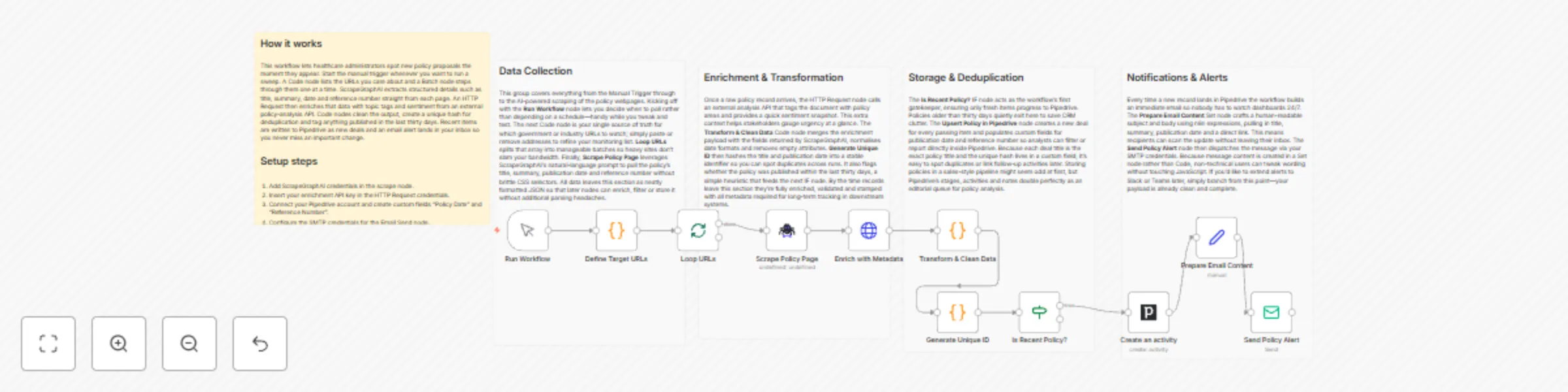
Healthcare policy monitoring with ScrapeGraphAI, Pipedrive and email alerts
Medical Research Tracker with Email and Pipedrive ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community contributed t...
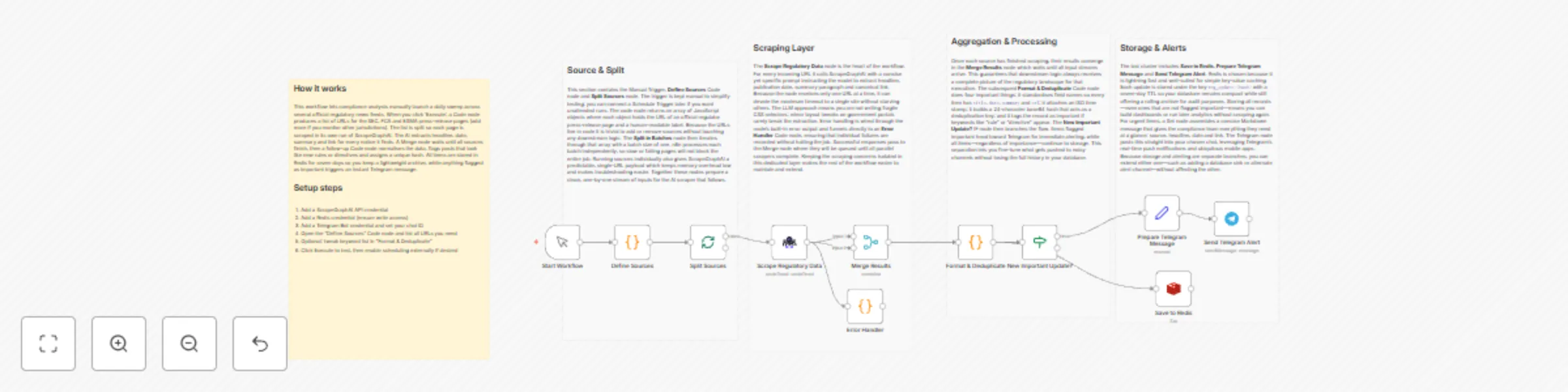
Monitor regulatory updates with ScrapeGraphAI and send alerts via Telegram
Breaking News Aggregator with Telegram and Redis ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community contributed te...

Track & alert public transport delays using ScrapeGraphAI, Teams and Todoist
Public Transport Delay Tracker with Microsoft Teams and Todoist ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community...
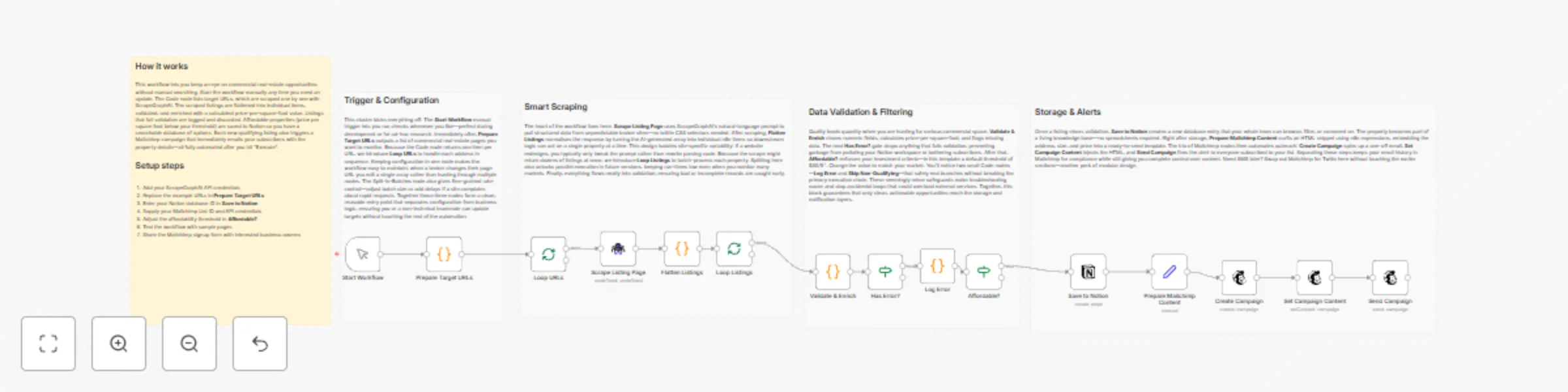
Automate commercial real estate monitoring with ScrapeGraphAI, Notion and Mailchimp
Property Listing Aggregator with Mailchimp and Notion ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community contribut...
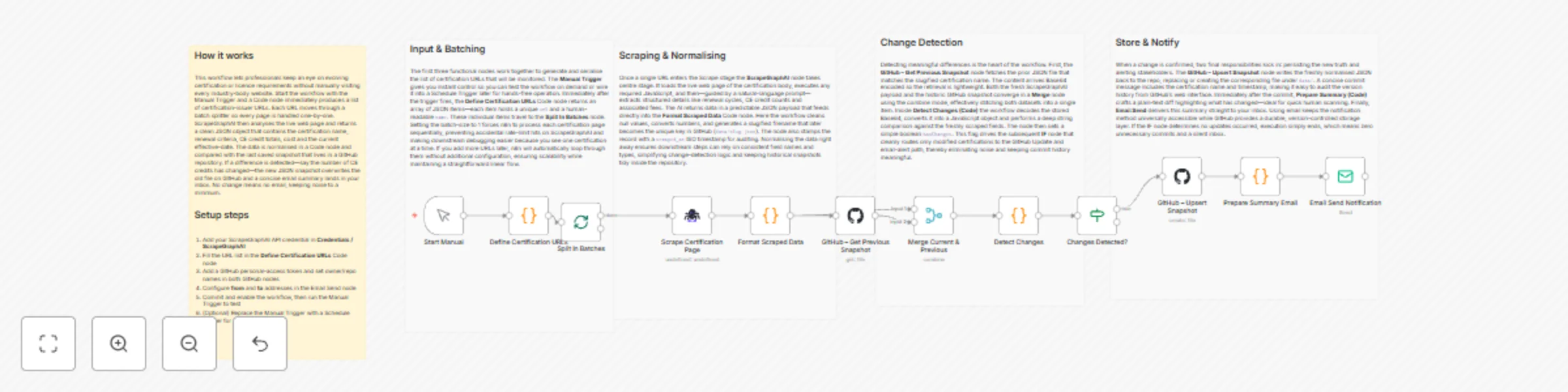
Track certification requirement changes with ScrapeGraphAI, GitHub and email
Job Posting Aggregator with Email and GitHub ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community contributed templa...
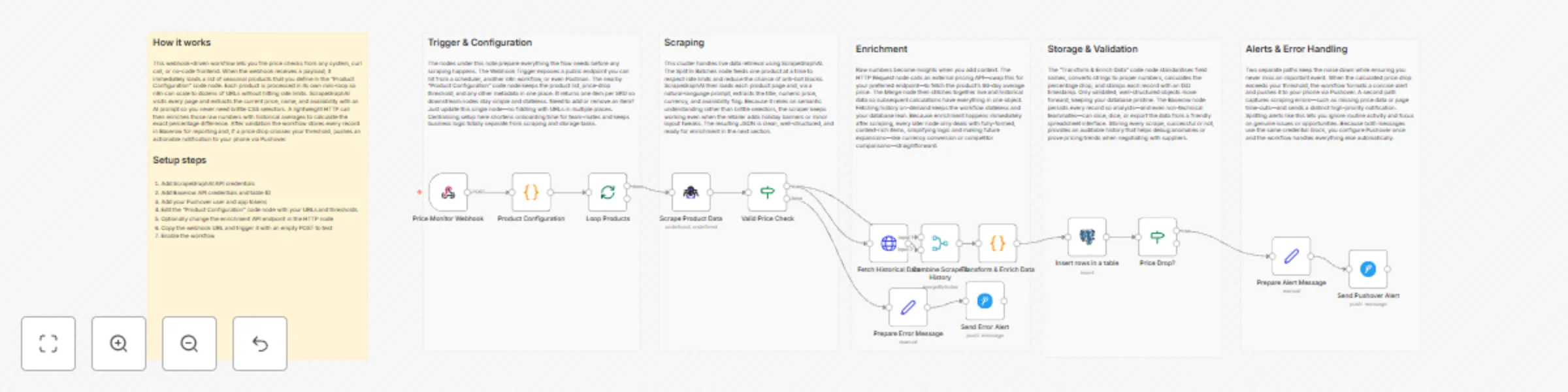
Track e-commerce price changes with ScrapeGraphAI, Baserow & Pushover alerts
Product Price Monitor with Pushover and Baserow ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community contributed tem...
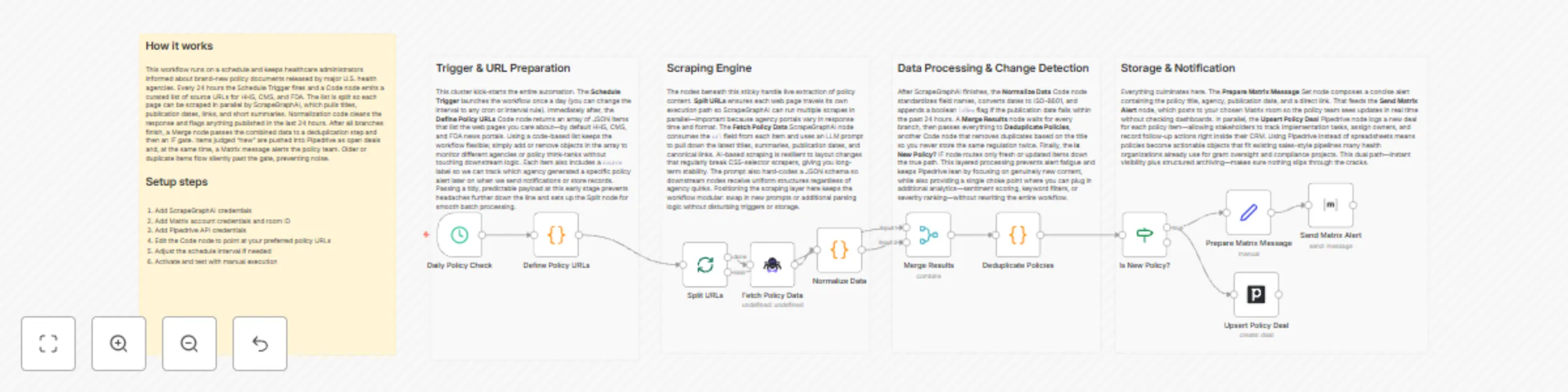
Healthcare policy monitoring with ScrapeGraphAI, Pipedrive and Matrix alerts
Medical Research Tracker with Matrix and Pipedrive ⚠️ COMMUNITY TEMPLATE DISCLAIMER: This is a community contributed...