D
digi-stud.io
2
Workflows
Workflows by digi-stud.io

Free advanced
Fetch hierarchical data records from Airtable with multi-level relationships
Airtable Hierarchical Record Fetcher Description This n8n workflow retrieves an Airtable record along with its relate...
d
digi-stud.io Engineering
7 Jul 2025
196
0
Free advanced
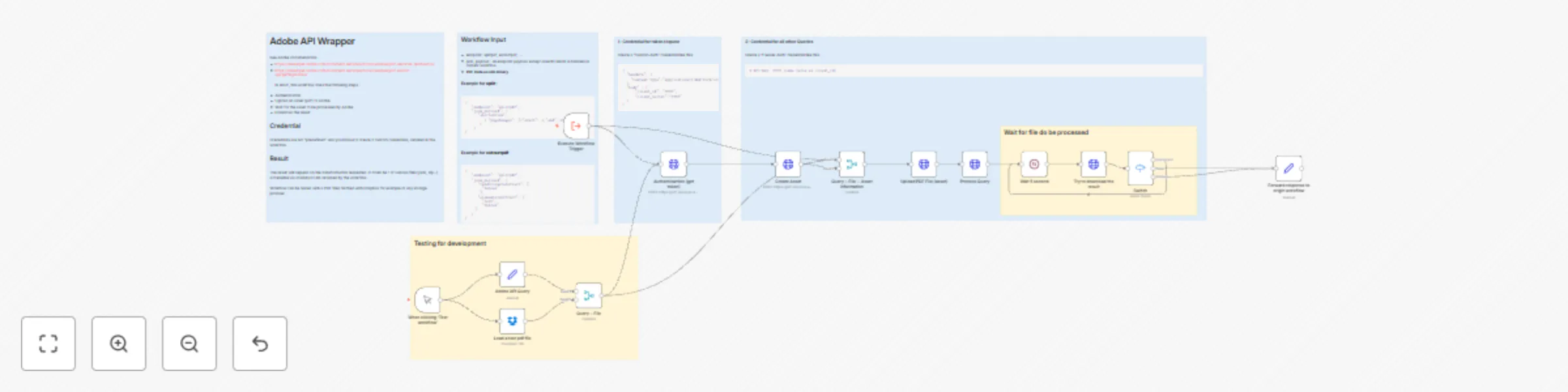
Manipulate PDF with Adobe developer API
Adobe developer API Did you know that Adobe provides an API to perform all sort of manipulation on PDF files : Split...
d
digi-stud.io Document Extraction
23 Sep 2024
4581
0