T
Tihomir Mateev
2
Workflows
Workflows by Tihomir Mateev
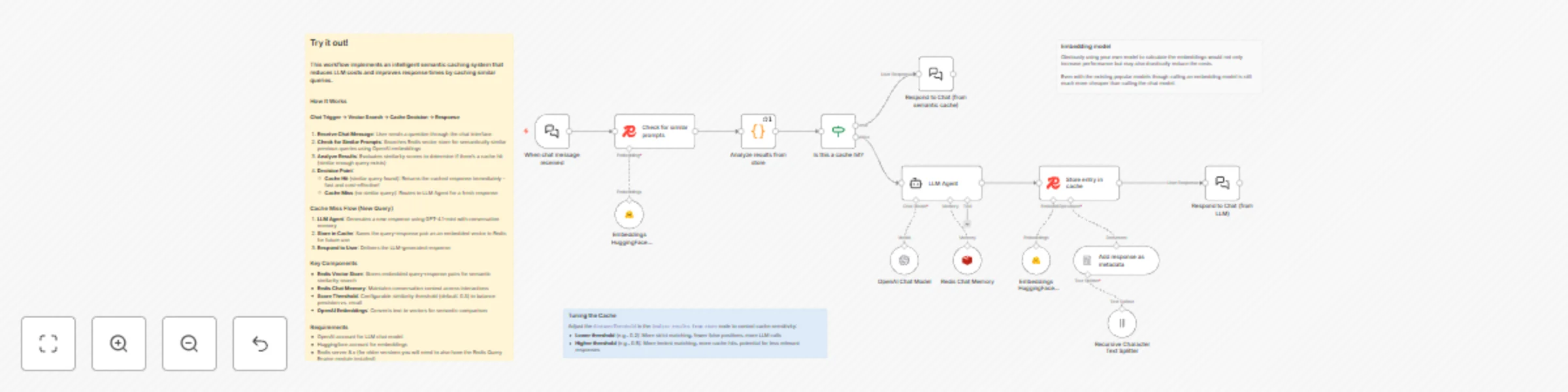
Free advanced
Reduce LLM Costs with Semantic Caching using Redis Vector Store and HuggingFace
Stop Paying for the Same Answer Twice Your LLM is answering the same questions over and over. "What's the weather?" "...
T
Tihomir Mateev Engineering
16 Nov 2025
1229
0

Free advanced
Chat with GitHub issues using OpenAI and Redis vector search
Chat with Your GitHub Issues Using AI 🤖 Ever wanted to just ask your repository what's going on instead of scrolling...
T
Tihomir Mateev Internal Wiki
14 Nov 2025
163
0