N
NovaNode
3
Workflows
Workflows by NovaNode

Free advanced
AI-powered WhatsApp chatbot for text, voice, images, and PDF with RAG
Who is this for? This template is designed for internal support teams, product specialists, and knowledge managers in...
N
NovaNode Support Chatbot
10 Jun 2025
151719
0
Free advanced
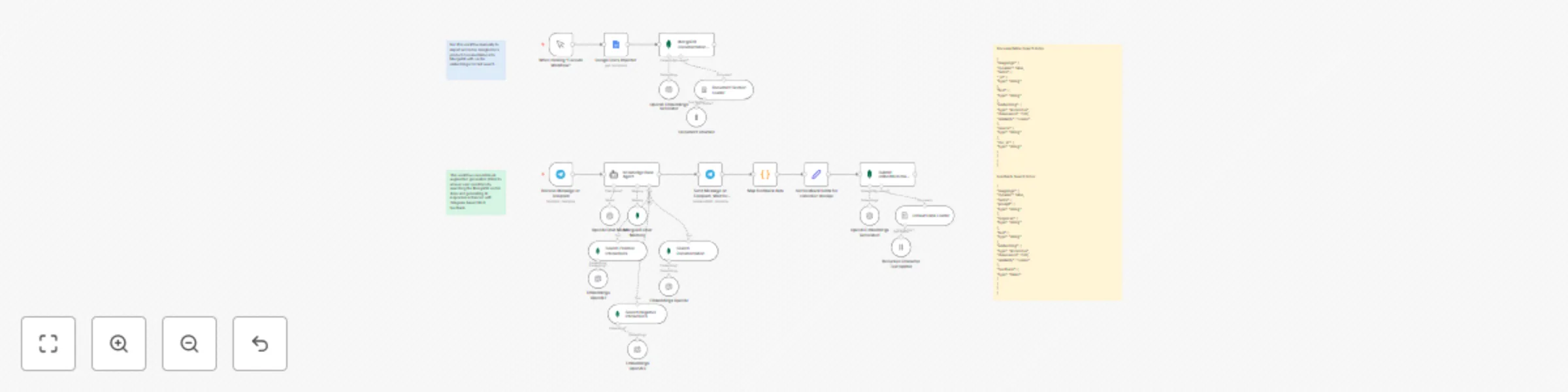
Build a chatbot with Reinforced Learning Human Feedback (RLHF) and RAG
Who is this for? This template is designed for internal support teams, product specialists, and knowledge managers wh...
N
NovaNode Internal Wiki
5 Jun 2025
6035
0
Free advanced
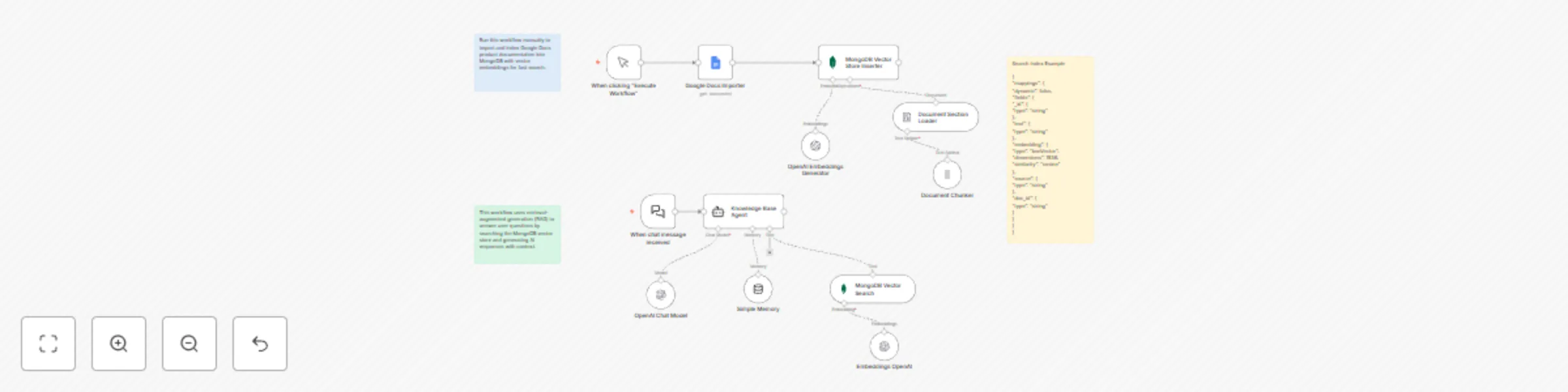
Build a knowledge base chatbot with OpenAI, RAG and MongoDB vector embeddings
Who is this for? This template is designed for internal support teams, product specialists, and knowledge managers in...
N
NovaNode Internal Wiki
31 May 2025
13113
0