T
Teddy
3
Workflows
Workflows by Teddy
Free intermediate
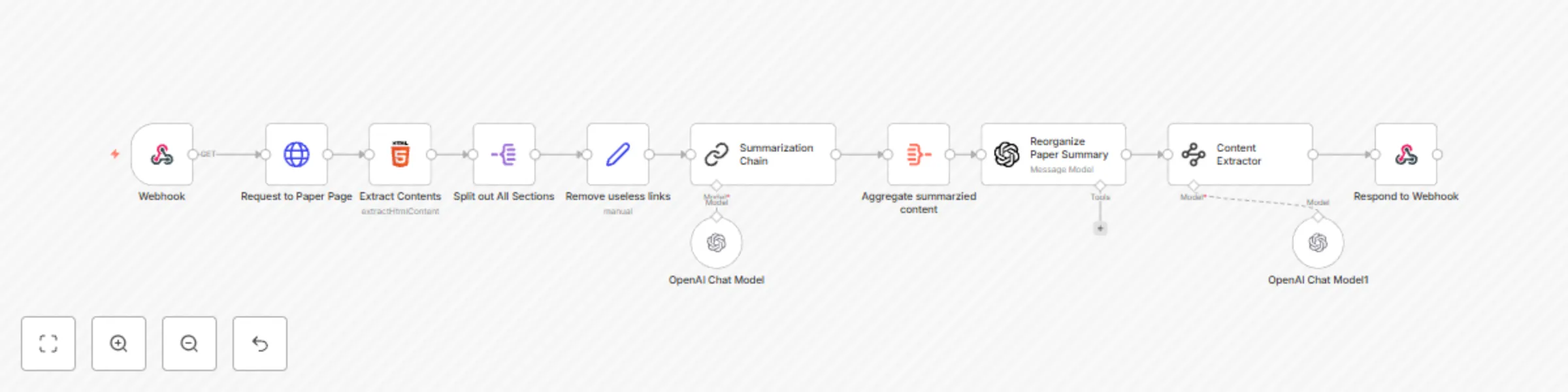
Arxiv paper summarization with ChatGPT
Webhook Paper Summarization Who is this for? This workflow is designed for researchers, students, and professionals w...
T
Teddy Document Extraction
14 Feb 2025
5174
0
Free intermediate
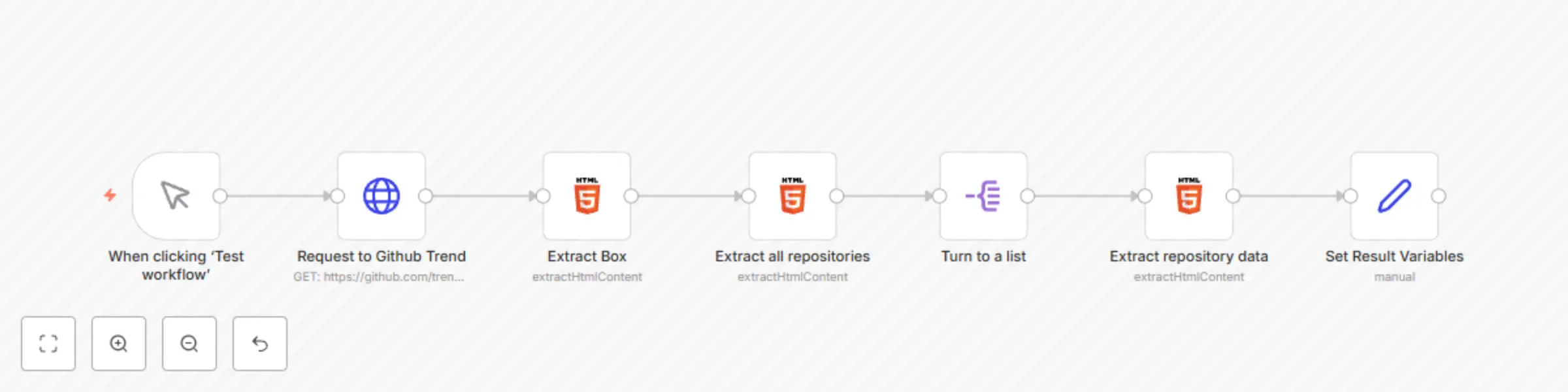
Scrape latest Github trending repositories
Scrape Latest 20 TechCrunch Articles Who is this for? This workflow is designed for developers, researchers, and data...
T
Teddy Market Research
8 Feb 2025
8821
0
Free intermediate
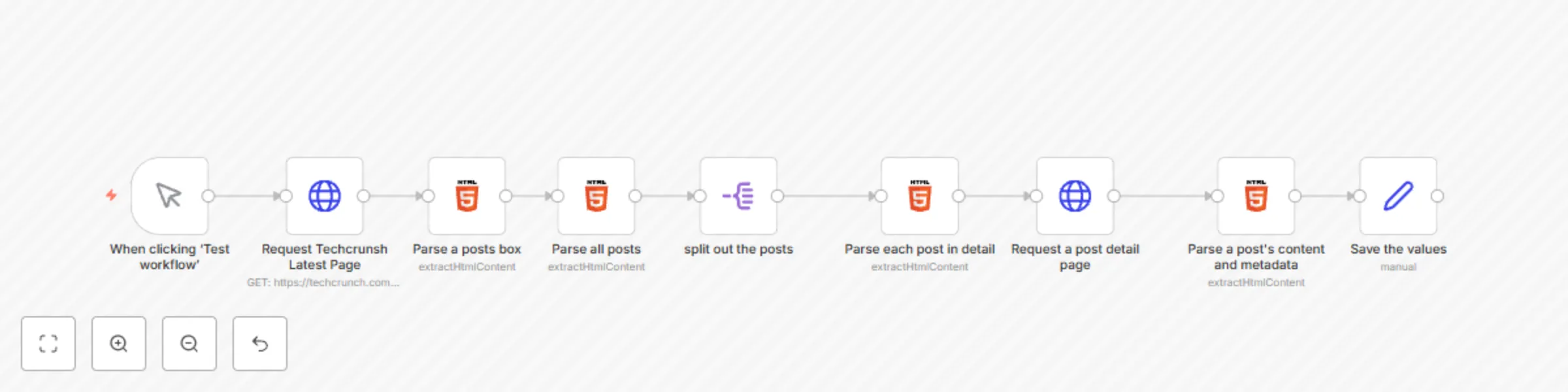
Scrape latest 20 TechCrunch articles
Retrieve 20 Latest TechCrunch Articles Who is this for? This workflow is designed for developers, content creators, a...
T
Teddy Market Research
1 Feb 2025
6650
0