S
Shiv Gupta
3
Workflows
Workflows by Shiv Gupta

Free advanced
Pinterest keyword-based content scraper with AI agent & BrightData automation
Pinterest Keyword Based Content Scraper with AI Agent & BrightData Automation Overview This n8n workflow automates Pi...
S
Shiv Gupta Market Research
24 Jun 2025
1743
0
Free intermediate
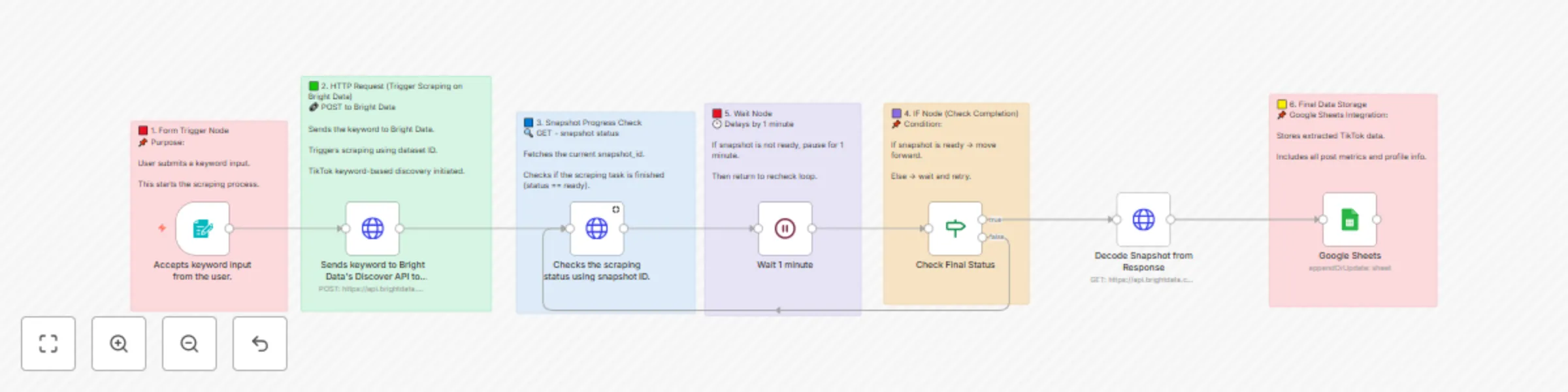
TikTok post scraper via keywords | Bright Data + Sheets integration
🎵 TikTok Post Scraper via Keywords Bright Data + Sheets Integration 📝 Workflow Description Automatically scrapes Ti...
S
Shiv Gupta Market Research
23 Jun 2025
3669
0
Free advanced
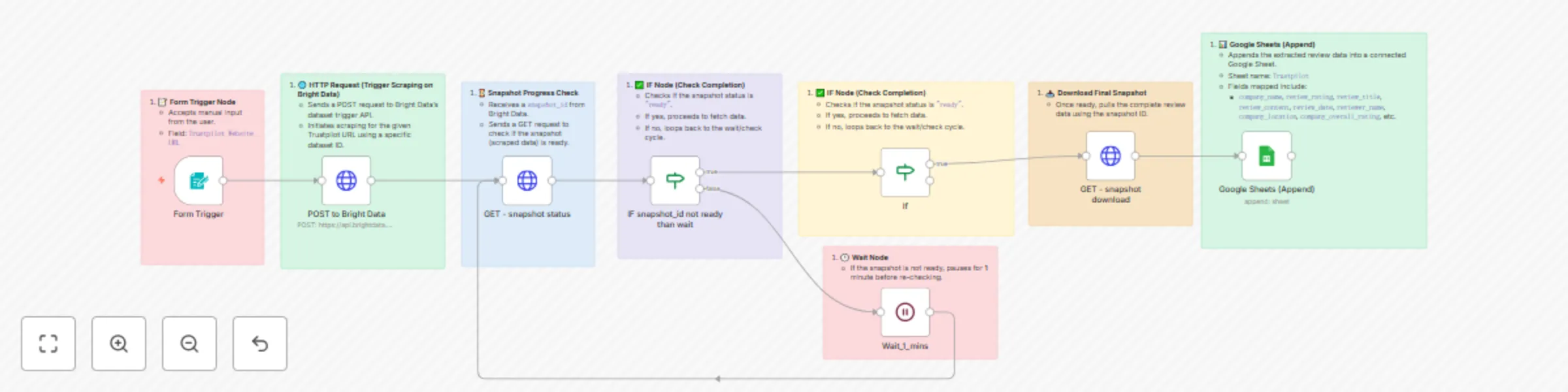
Trustpilot insights scraper: Auto reviews via Bright Data + Google Sheets sync
Trustpilot Insights Scraper: Auto Reviews via Bright Data + Google Sheets Sync Overview A comprehensive n8n automatio...
S
Shiv Gupta Market Research
23 Jun 2025
277
0