scrapeless official
Workflows by scrapeless official

AI-powered research assistant with Linear, Scrapeless, and Claude
Brief Overview This workflow integrates Linear, Scrapeless, and Claude AI to create an AI research assistant that can...

Generate SEO-optimized blog content with Gemini, Scrapeless and Pinecone RAG
This workflow contains community nodes that are only compatible with the self hosted version of n8n. How it works Thi...
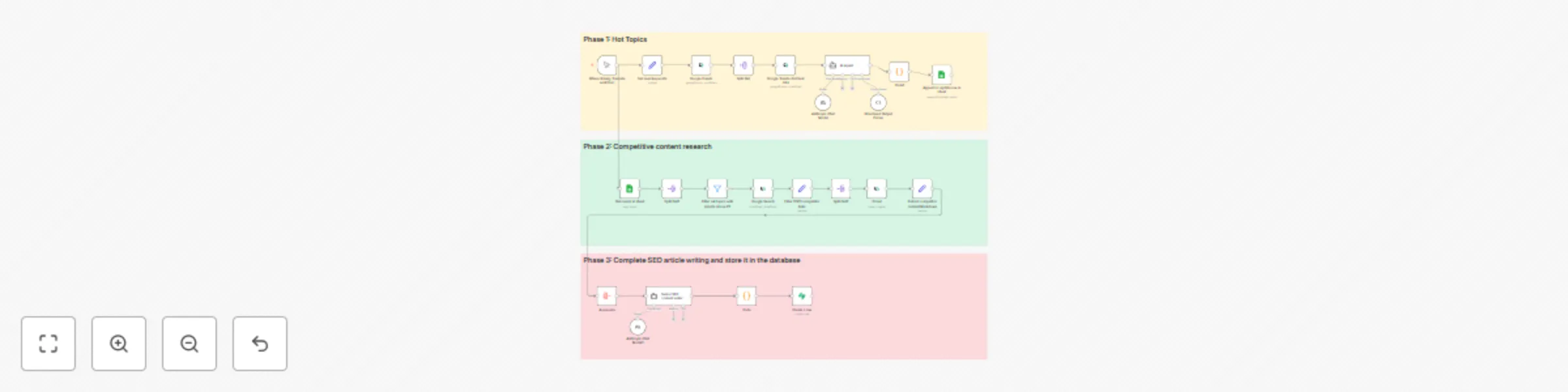
Automated SEO content engine with Claude AI, Scrapeless, and competitor analysis
This workflow contains community nodes that are only compatible with the self hosted version of n8n. How it works Thi...
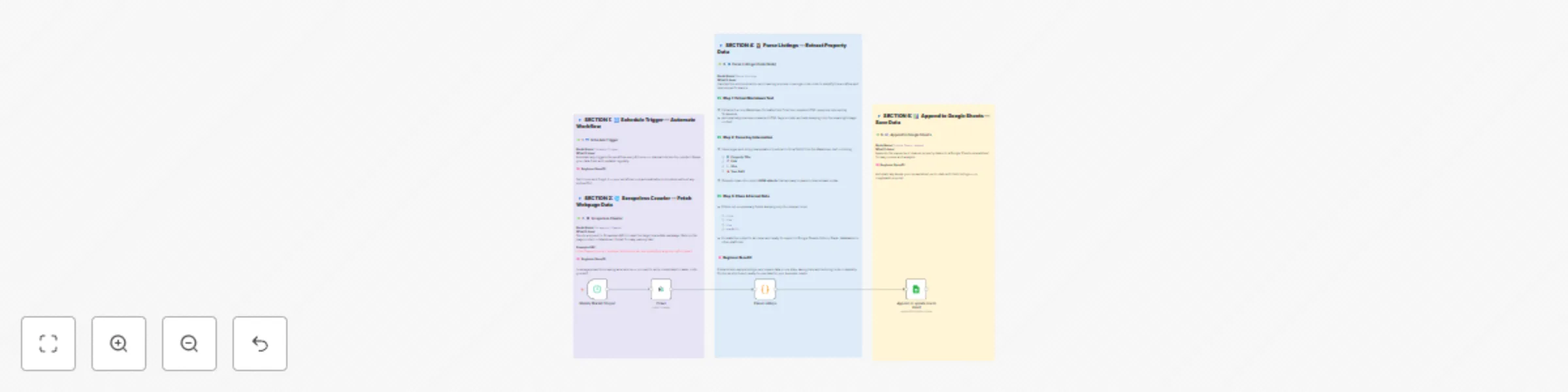
Automate real estate listing scraper with Scrapeless and Google Sheets
Brief Overview This automation template helps you track the latest real estate listings from the LoopNet platform. By...
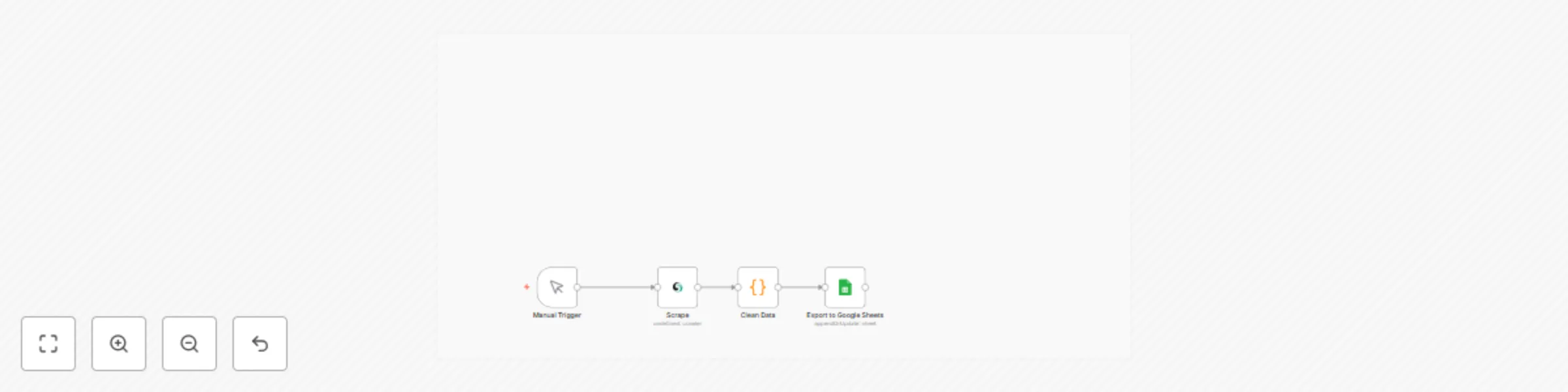
Automated job finder agent
This workflow contains community nodes that are only compatible with the self hosted version of n8n. Brief Overview T...
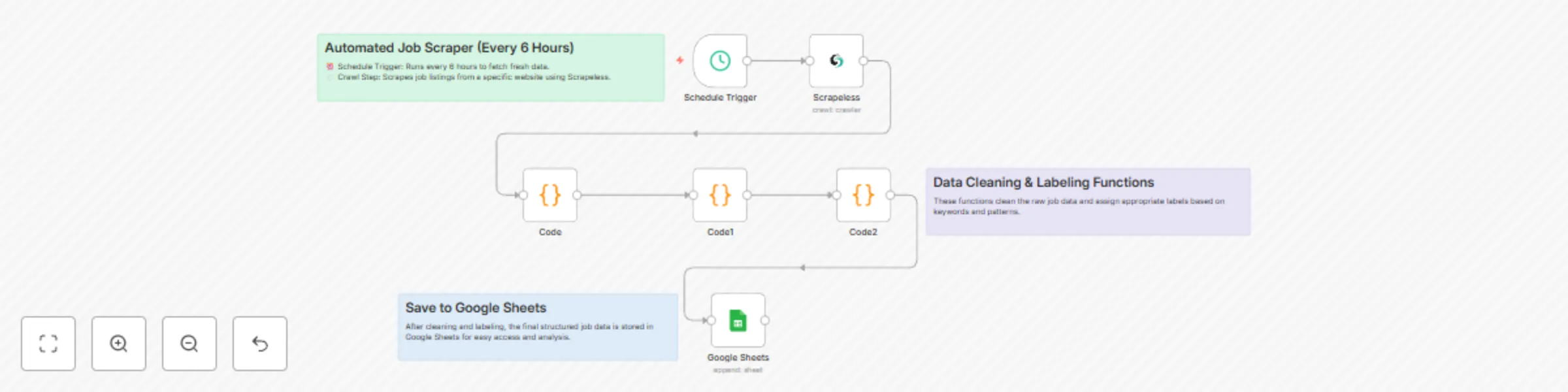
Automate lead scraping with Scrapeless to Google Sheets with data cleaning
This workflow contains community nodes that are only compatible with the self hosted version of n8n. Prerequisites A...

Intelligent B2B lead generation workflow using Scrapeless and Claude
> ⚠️ Disclaimer : This workflow uses Scrapeless and Claude AI via community nodes , which require n8n self hosted...
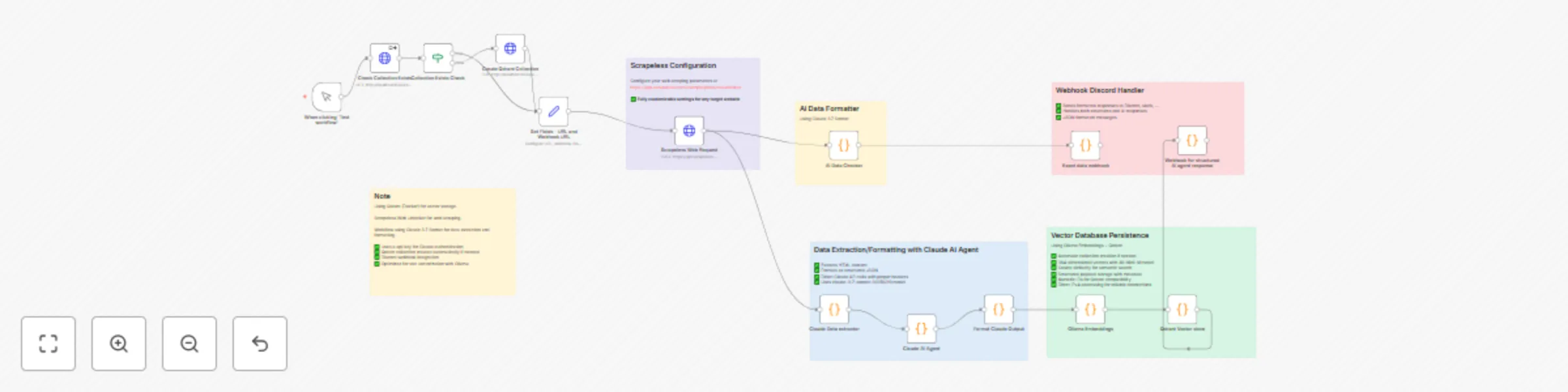
Create AI-ready vector datasets from web content with Claude, Ollama & Qdrant
AI Powered Web Data Pipeline with n8n How It Works This workflow builds an AI powered web data pipeline that automate...