PDF Vector
Workflows by PDF Vector
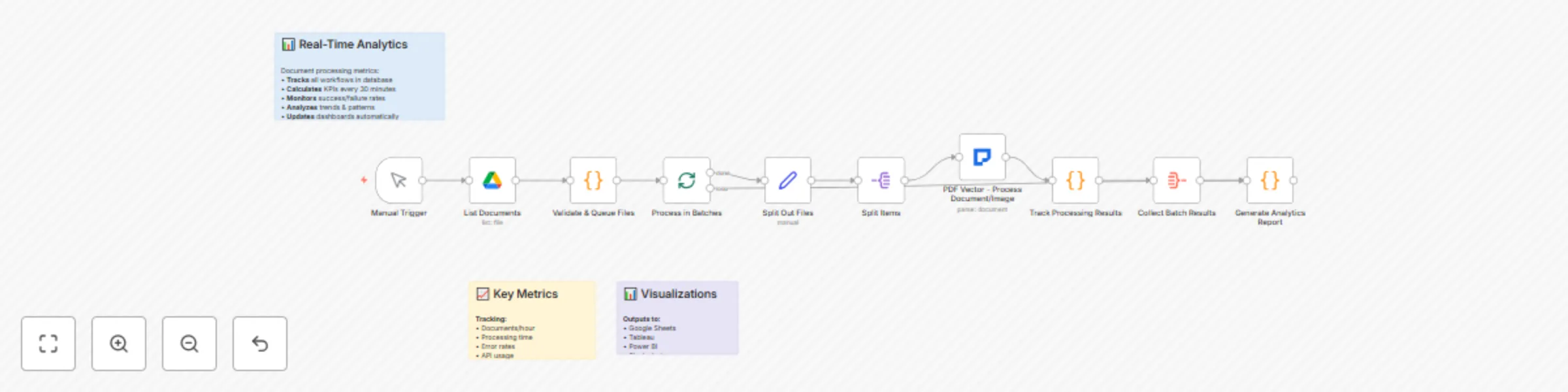
Process documents with OCR, analytics & Google Drive using PDF Vector
Organizations dealing with high volume document processing face challenges in efficiently handling diverse document t...
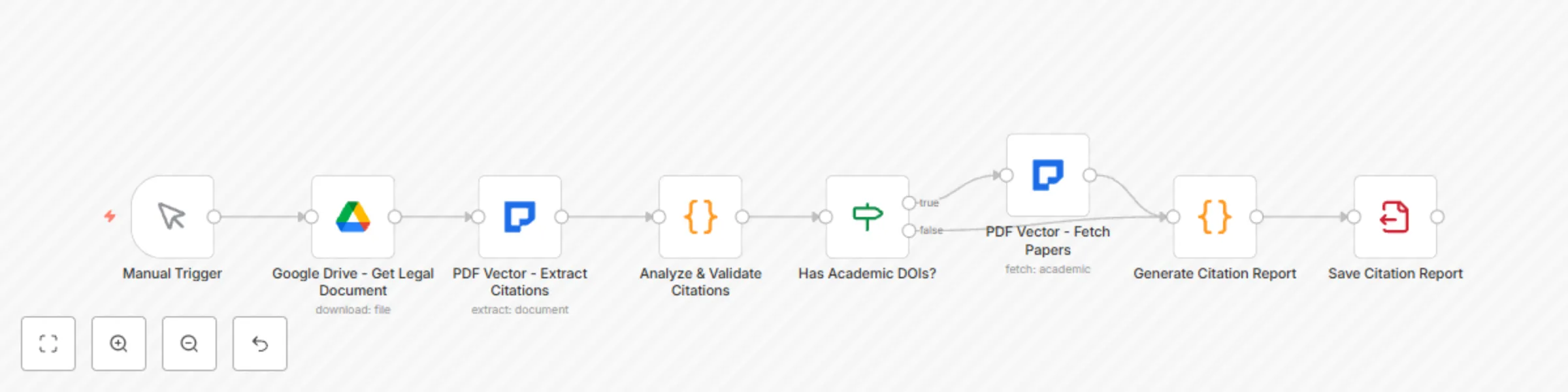
Extract & validate legal citations from documents with PDF Vector AI
Legal professionals spend countless hours manually checking citations and building citation indexes for briefs, memor...
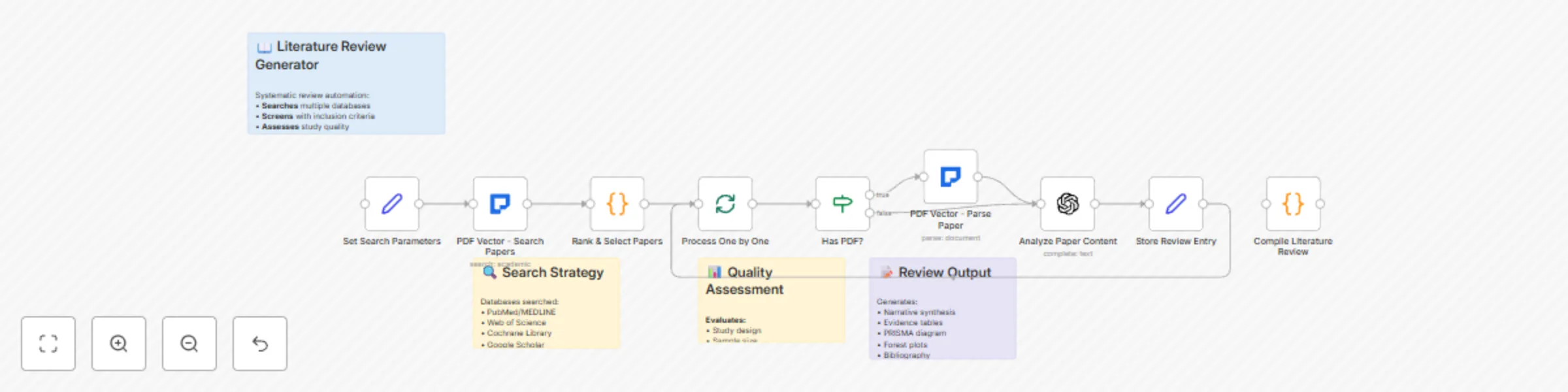
Automate academic literature reviews with GPT-4 and multi-database search
Conducting comprehensive literature reviews is one of the most time consuming aspects of academic research. This work...
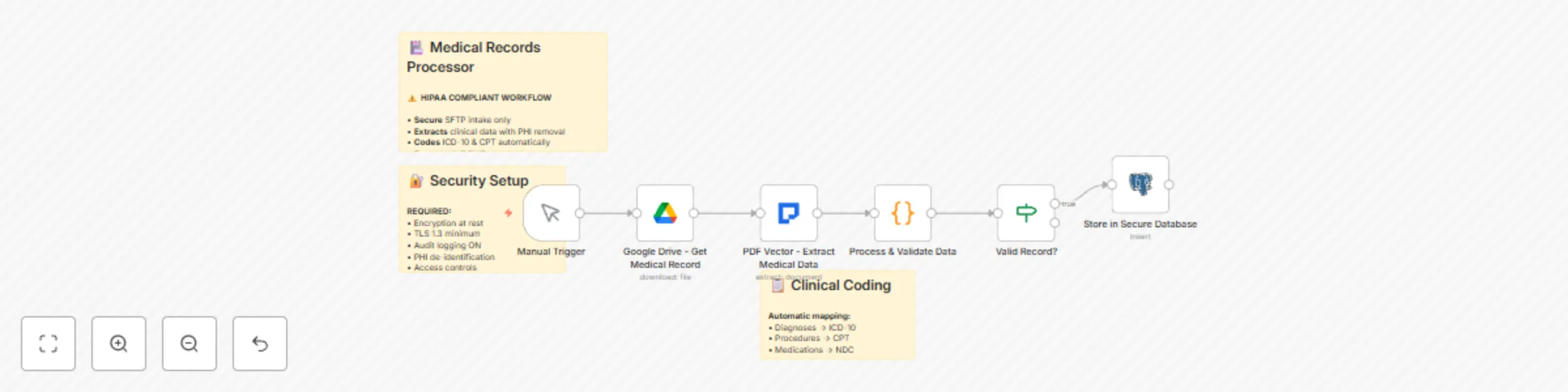
Extract clinical data from medical documents with PDF vector & HIPAA compliance
Healthcare organizations face significant challenges in digitizing and processing medical records while maintaining s...

Automated receipt processing with tax categorization using PDF vector & Google Drive
Businesses and freelancers often struggle with the tedious task of manually processing receipts for expense tracking...
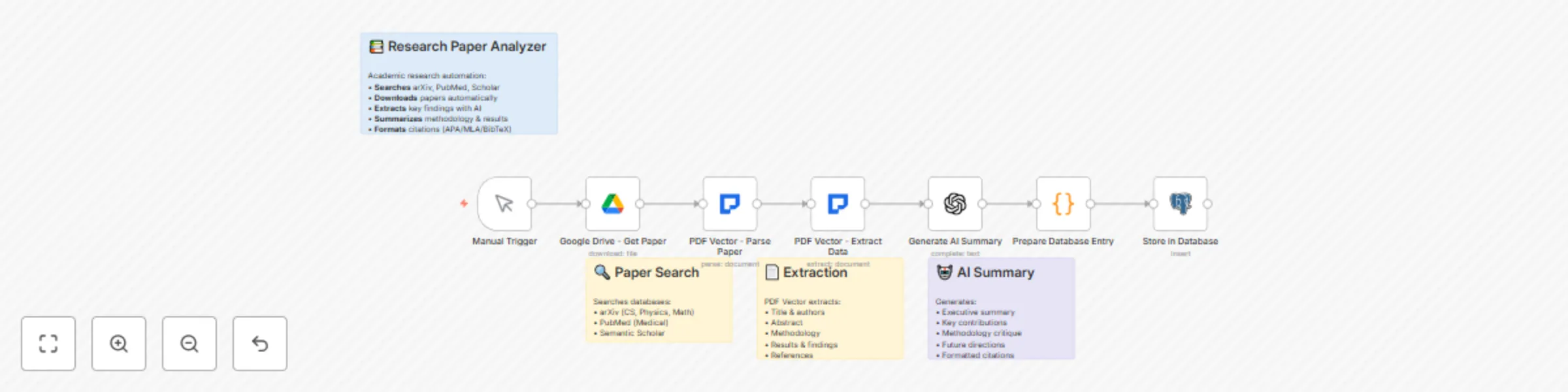
Research paper analysis system with PDF vector, OCR, GPT-4, and Google Drive
Researchers and academic institutions need efficient ways to process and analyze large volumes of research papers and...
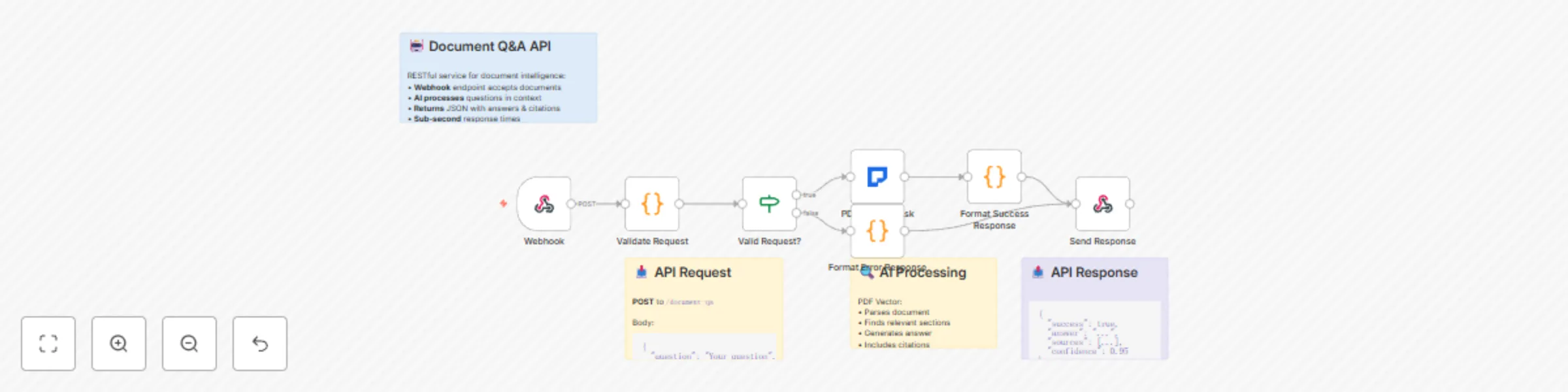
Build document Q&A API with PDF vector and webhooks
Organizations struggle to make their document repositories searchable and accessible. Users waste time searching thro...
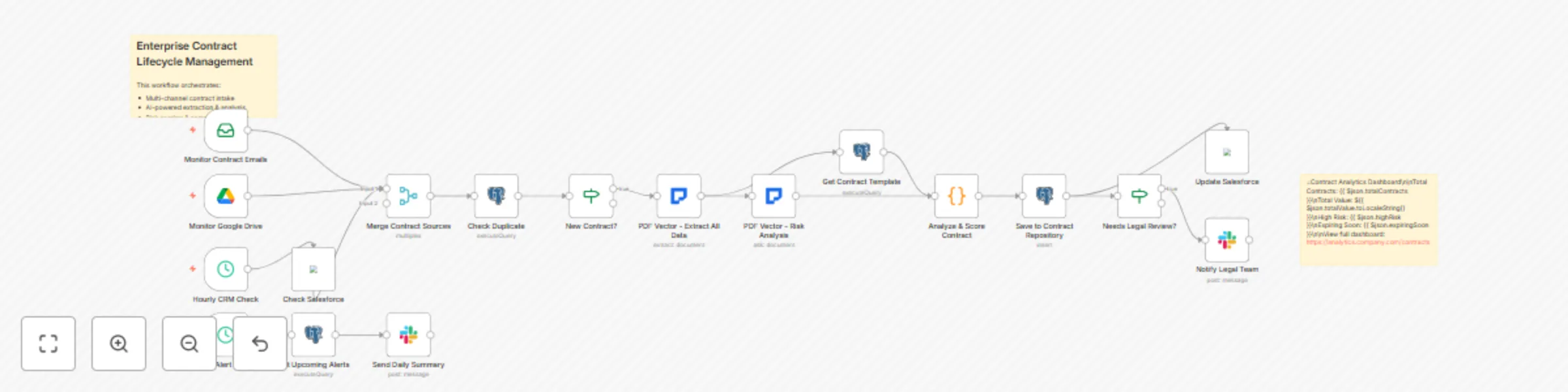
Enterprise contract lifecycle management with AI risk analysis
Transform your contract management process with this enterprise grade workflow that handles the complete contract lif...
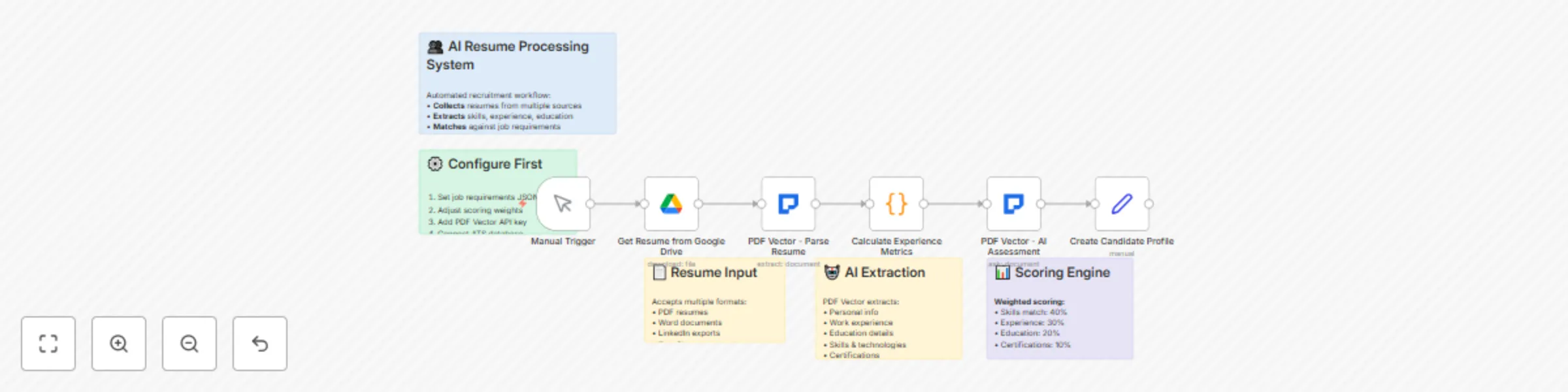
Parse and score resumes with PDF Vector AI
HR departments and recruiters spend countless hours manually reviewing resumes, often missing qualified candidates du...
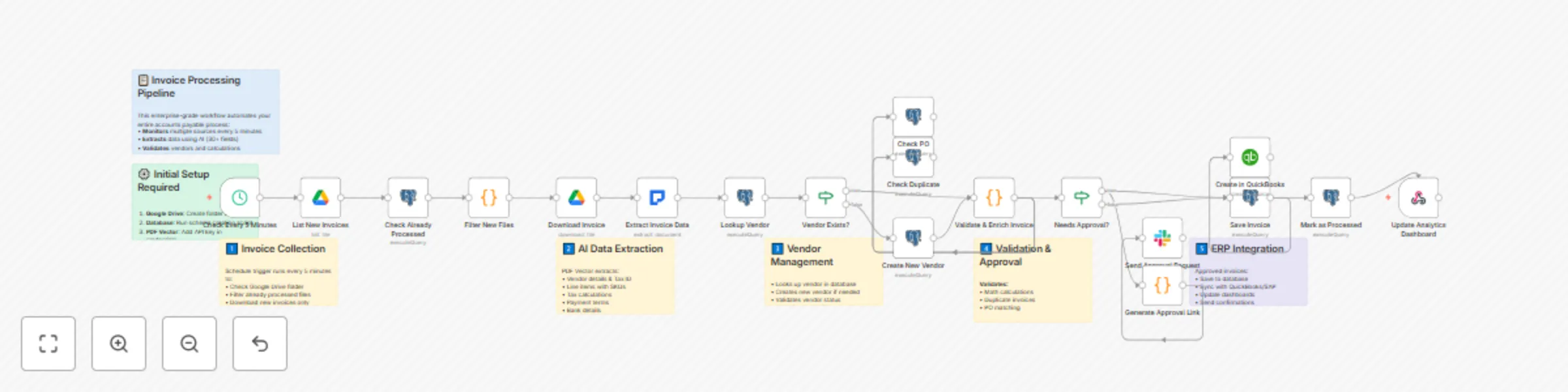
Extract & store invoice data with PDF vector, Google Drive & database
Transform your accounts payable department with this enterprise grade invoice processing solution. This workflow auto...
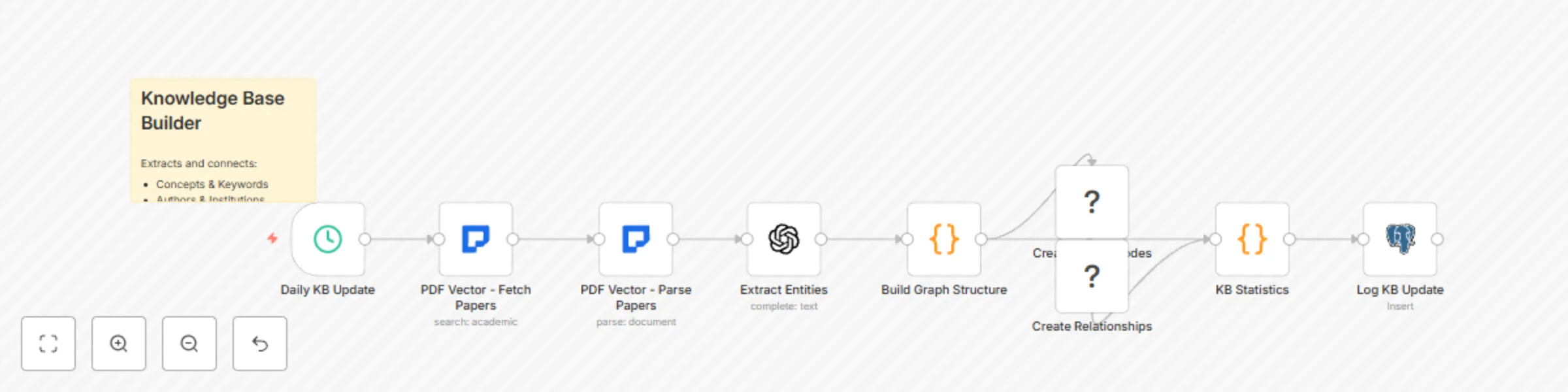
Build academic knowledge graph from research papers with PDF vector, GPT-4 and Neo4j
This workflow contains community nodes that are only compatible with the self hosted version of n8n. Transform Resear...
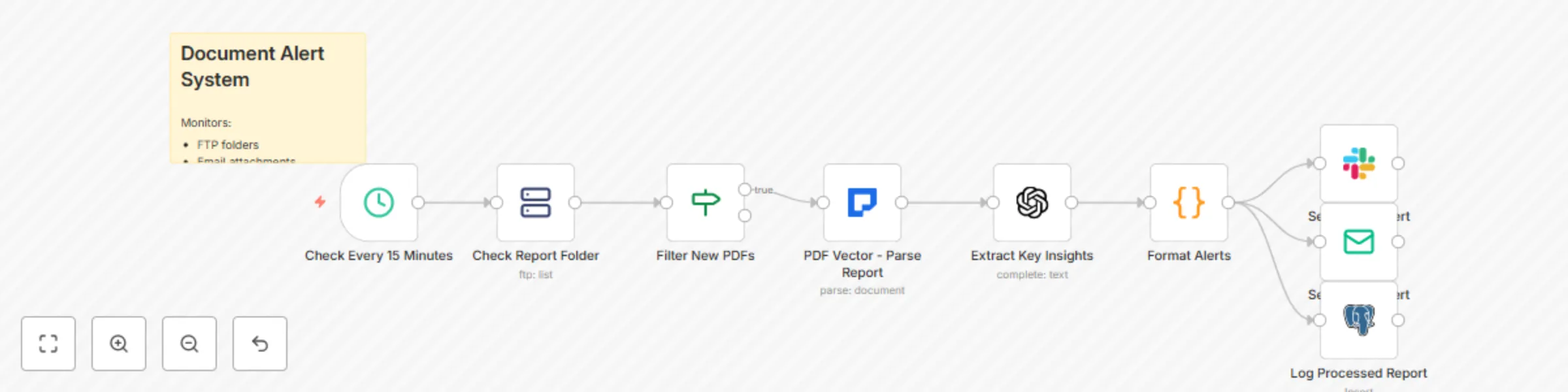
Pdf report monitor with GPT-3.5 insights and Slack/Email alerts
This workflow contains community nodes that are only compatible with the self hosted version of n8n. Intelligent Docu...
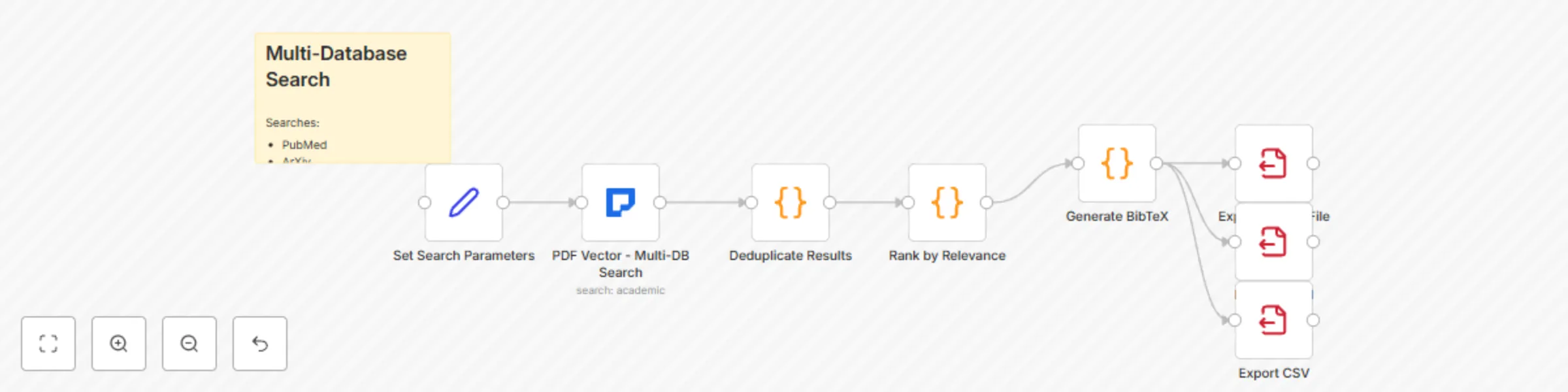
Academic research search across five databases with PDF vector & multiple exports
This workflow contains community nodes that are only compatible with the self hosted version of n8n. Description: Uni...
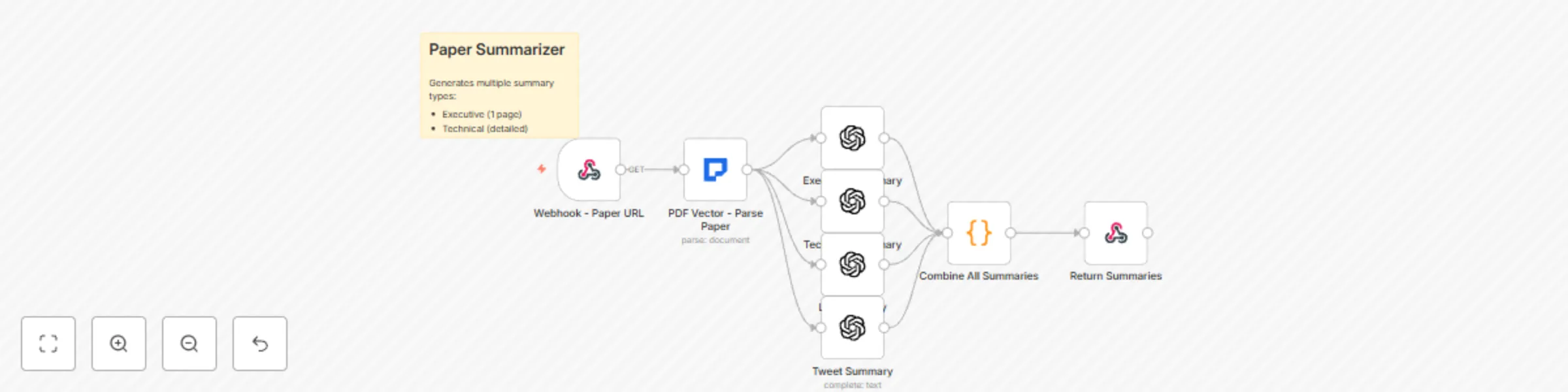
Generate multi-format research paper summaries with GPT-4 and PDF vector
This workflow contains community nodes that are only compatible with the self hosted version of n8n. Transform Comple...
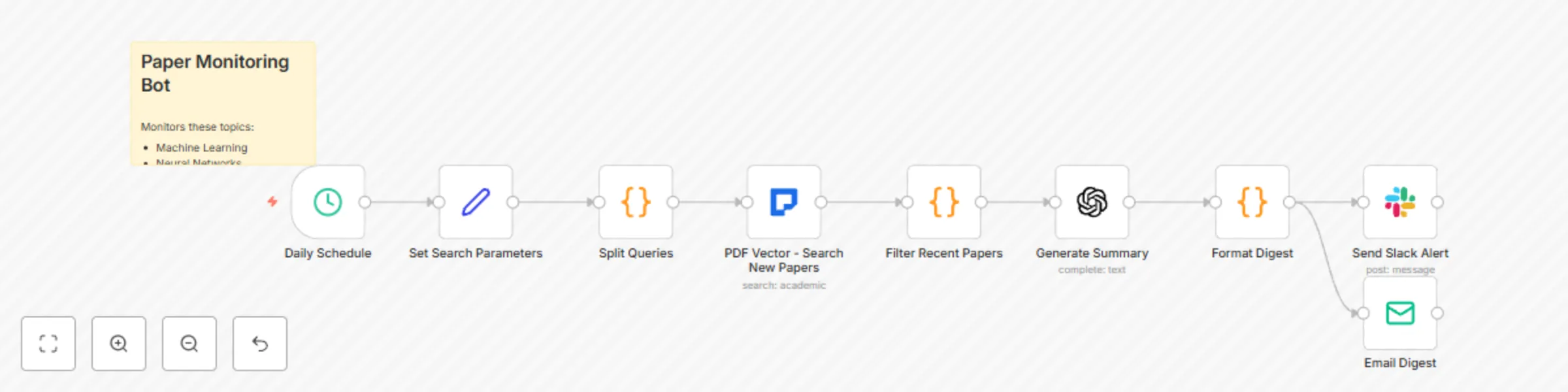
Automated academic paper monitoring with PDF vector, GPT-3.5, & Slack alerts
This workflow contains community nodes that are only compatible with the self hosted version of n8n. Automated Academ...
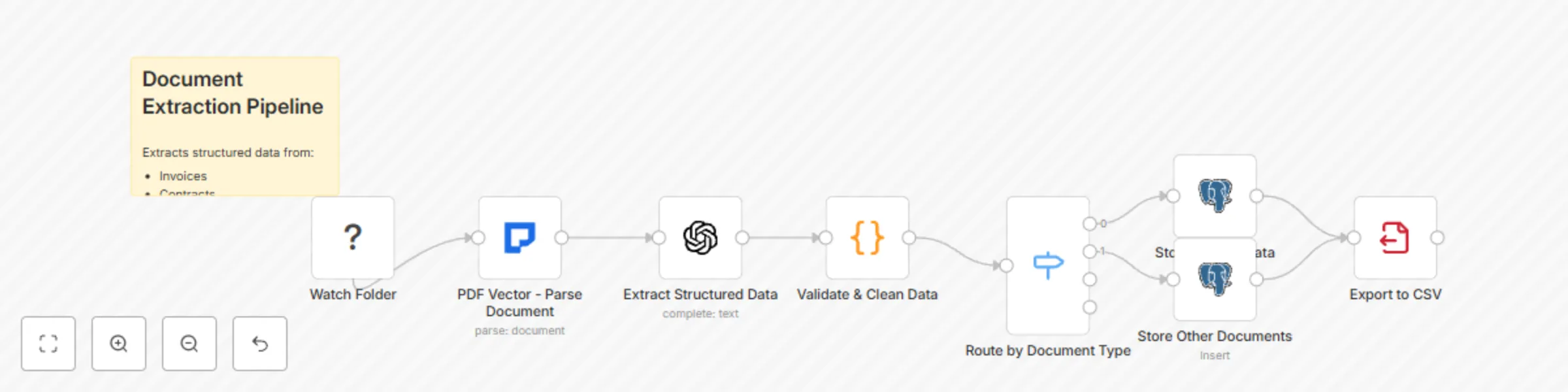
Extract data from documents with GPT-4, PDFVector & PostgreSQL export
Intelligent Document Processing & Data Extraction Extract structured data from unstructured documents like invoices,...
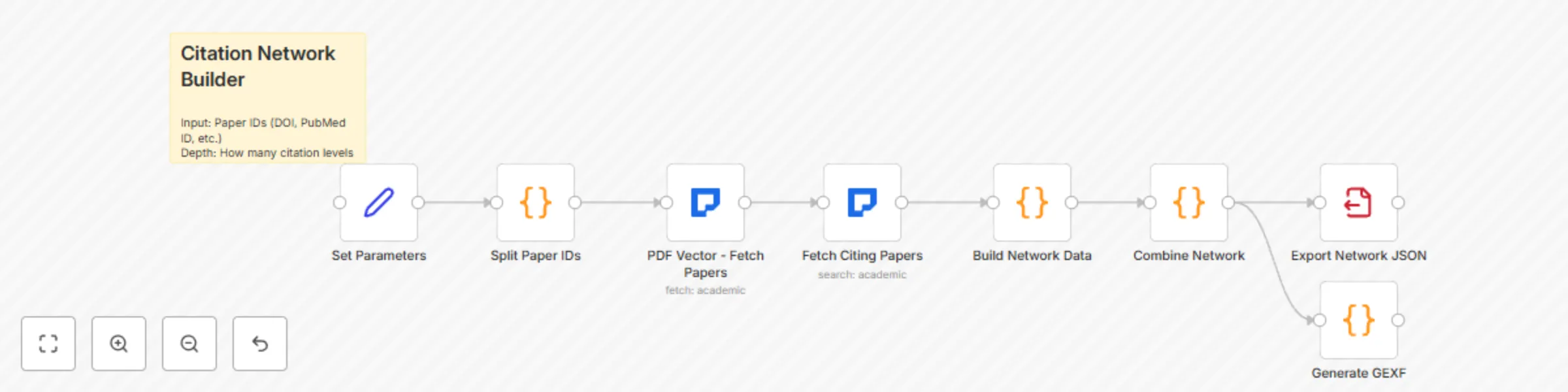
Build academic citation networks with PDF Vector API for Gephi visualization
This workflow contains community nodes that are only compatible with the self hosted version of n8n. Build Citation N...
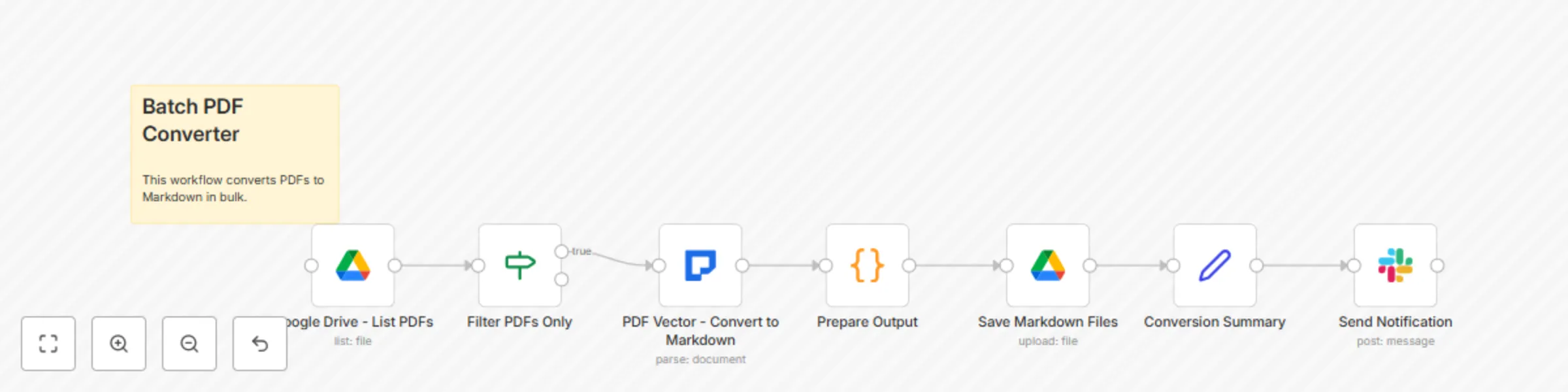
Bulk PDF to markdown conversion with Google Drive & LLM-powered parsing
This workflow contains community nodes that are only compatible with the self hosted version of n8n. High Volume PDF...
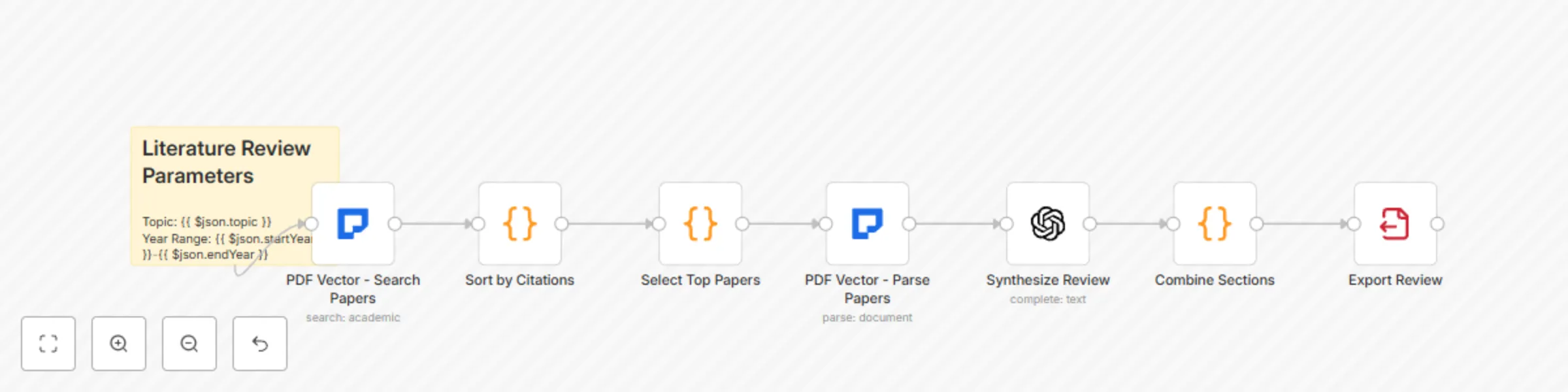
Build comprehensive literature reviews with GPT-4 and multi-database search
This workflow contains community nodes that are only compatible with the self hosted version of n8n. Comprehensive Li...

Parse & analyze research papers with PDF vector, GPT-4 and database storage
Automated Research Paper Analysis Pipeline This workflow automatically analyzes research papers by: Parsing PDF docum...