P
Pavel Duchovny
2
Workflows
Workflows by Pavel Duchovny

Free intermediate
Travel planning assistant with MongoDB Atlas, Gemini LLM and vector search
Building agentic AI workflows often requires multiple moving parts: memory management, document retrieval, vector sim...
P
Pavel Duchovny Personal Productivity
16 Apr 2025
3386
0
Free intermediate
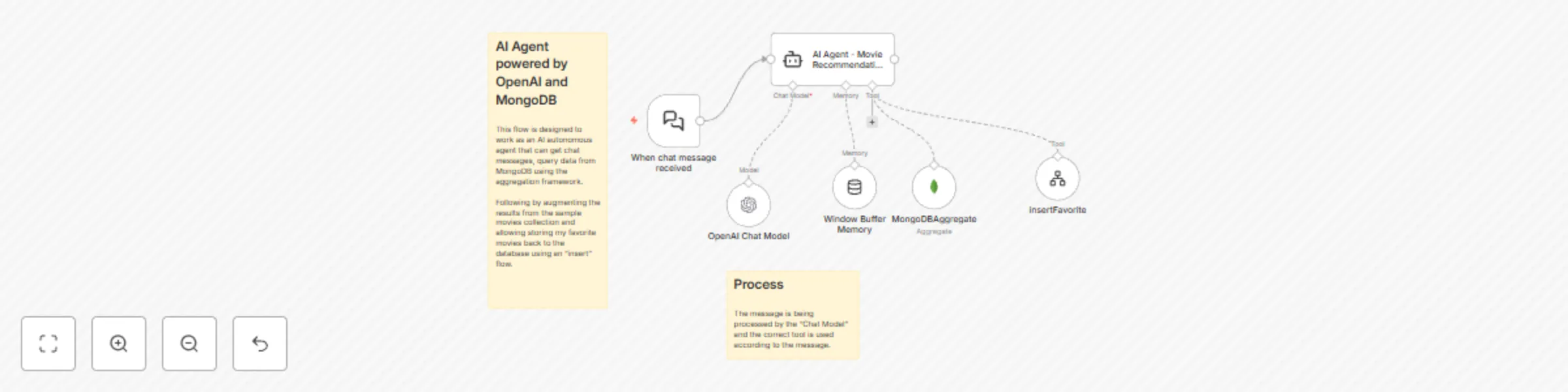
MongoDB AI agent - intelligent movie recommendations
Who is this for? This workflow is designed for: Database administrators and developers working with MongoDB Content m...
P
Pavel Duchovny Engineering
17 Nov 2024
3048
0