Onur
Workflows by Onur
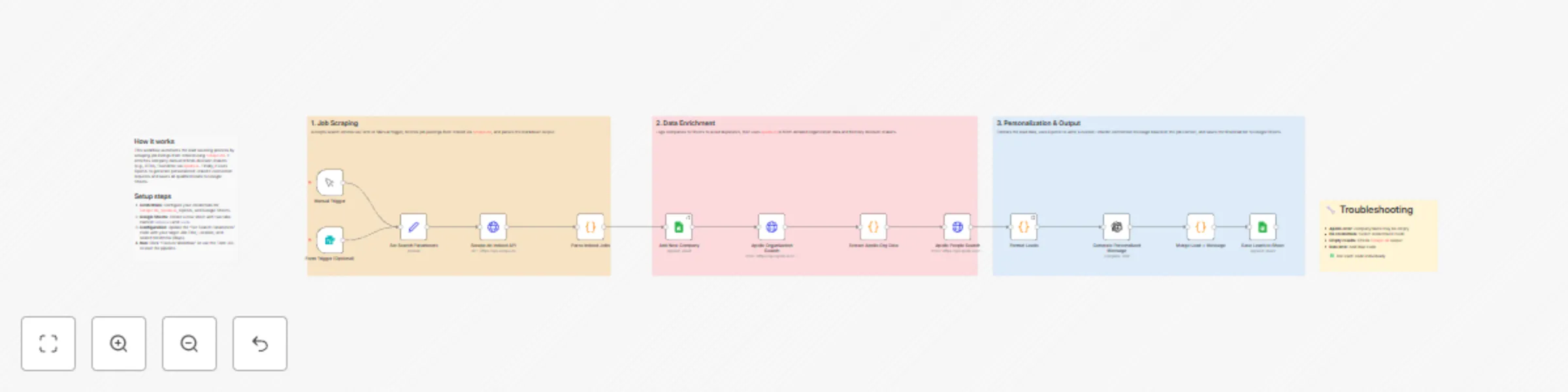
Job post to sales lead pipeline with Scrape.do, Apollo.io & OpenAI
Lead Sourcing by Job Posts For Outreach With Scrape.do API & Open AI & Google Sheets Overview This n8n workflow autom...
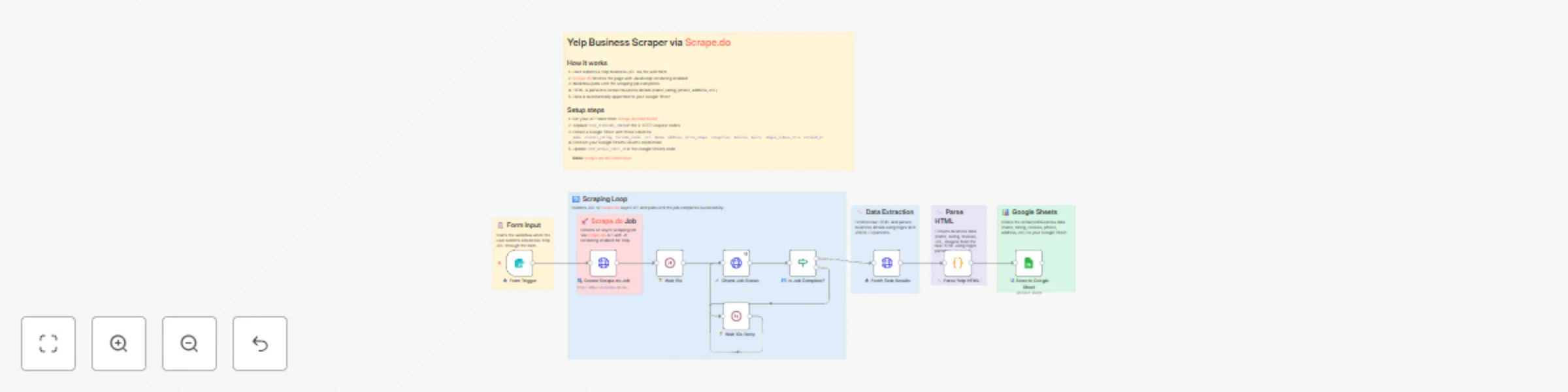
Scrape Yelp business data with Scrape.do API & Google Sheets storage
Yelp Business Scraper by URL via Scrape.do API with Google Sheets Storage Overview This n8n workflow automates the pr...
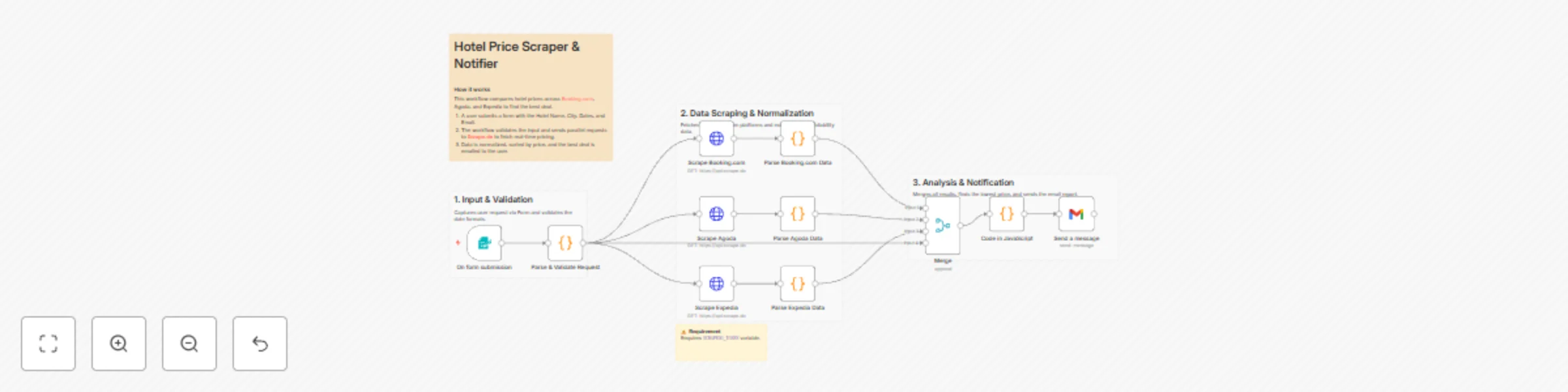
Compare hotel prices across booking platforms with Scrape.do and Google Sheets
🏨 Hotel Price Comparison Workflow with Scrape.do This template requires a self hosted n8n instance to run. A complet...
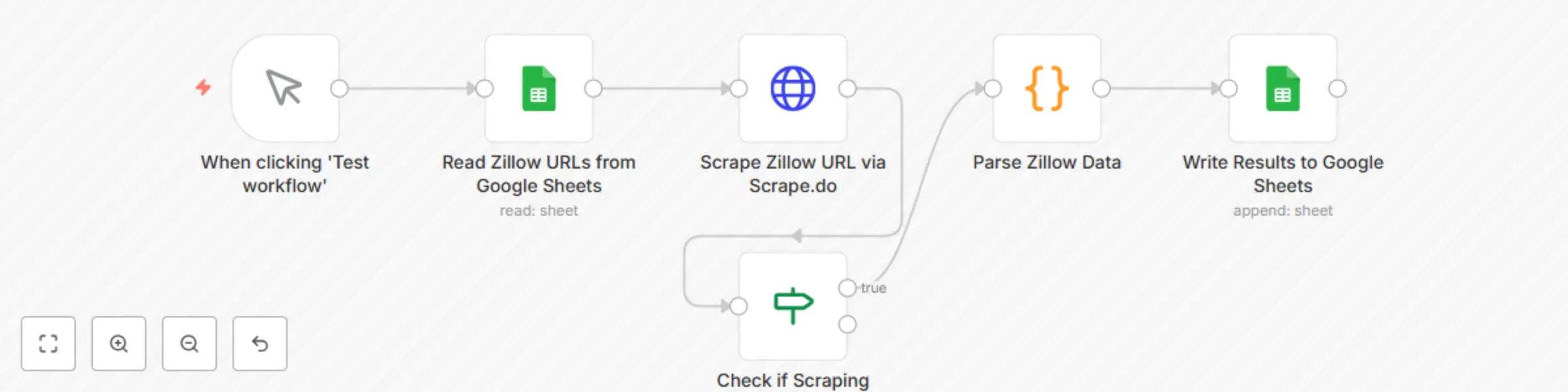
Extract Zillow property data to Google Sheets with Scrape.do
🏠 Extract Zillow Property Data to Google Sheets with Scrape.do This template requires a self hosted n8n instance to...
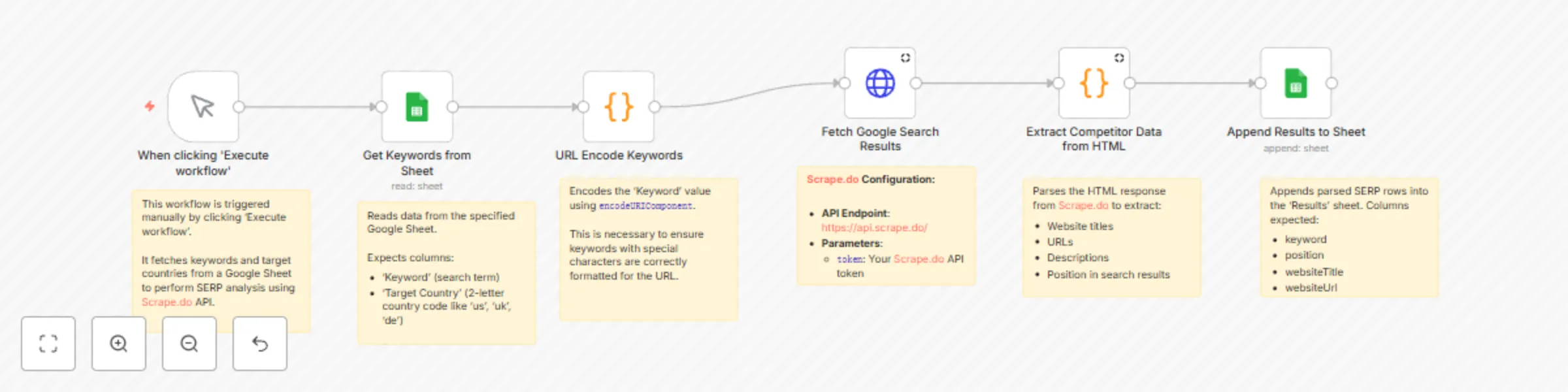
SERP competitor research with Scrape.do API & Google Sheets
🔍 Extract Competitor SERP Rankings from Google Search to Sheets with Scrape.do This template requires a self hosted...
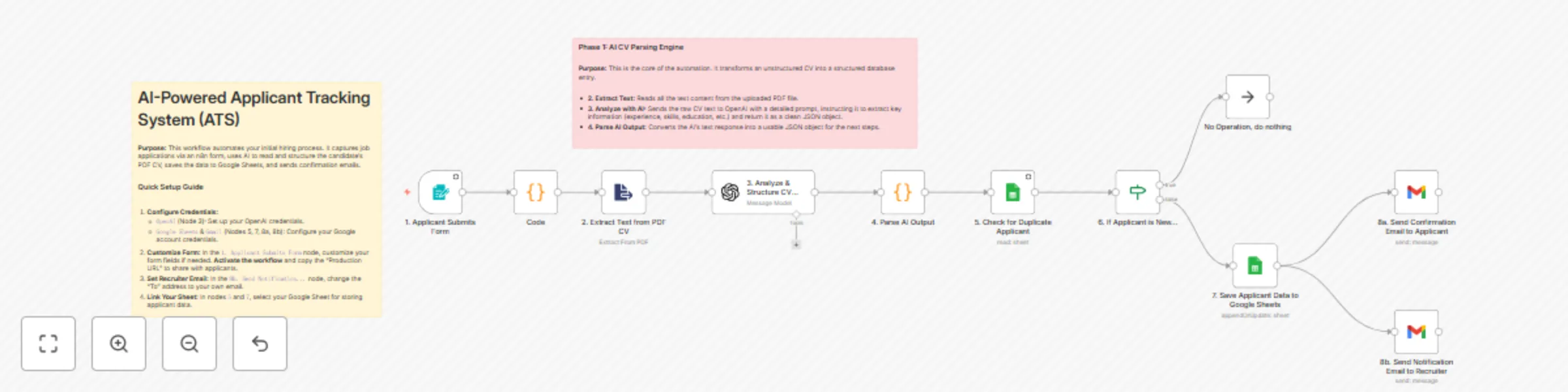
Automate applicant tracking with GPT-4.1 CV parsing, Google Sheets and Gmail alerts
Template Description: > Stop manually reading every CV and copy pasting data into a spreadsheet. This workflow act...
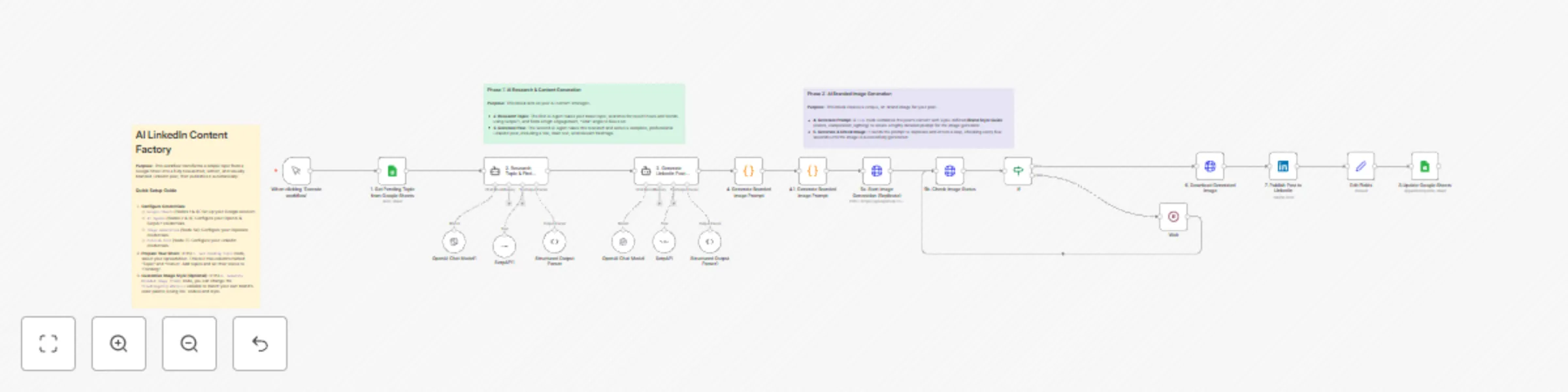
LinkedIn content factory with OpenAI research & Replicate branded images
Template Description: > Never run out of high quality LinkedIn content again. This workflow is a complete content...
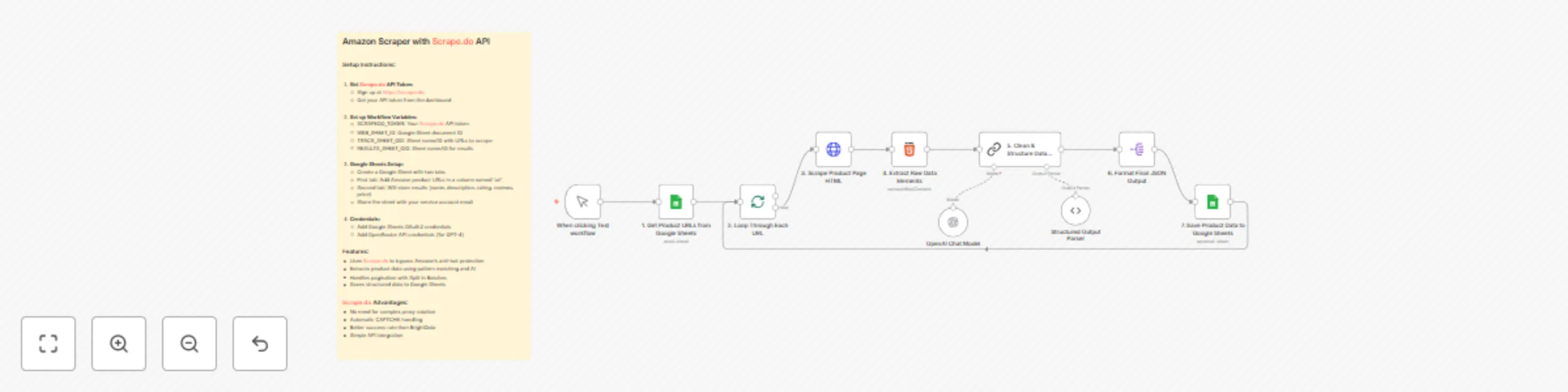
Extract Amazon product data with Scrape.do, GPT-4 & Google Sheets
Amazon Product Scraper with Scrape.do & AI Enrichment > This workflow is a fully automated Amazon product data ext...

Automated B2B lead generation: Google Places, Scrape.do & AI enrichment
Automated B2B Lead Generation: Google Places, Scrape.do & AI Enrichment This workflow is a powerful, fully automated...
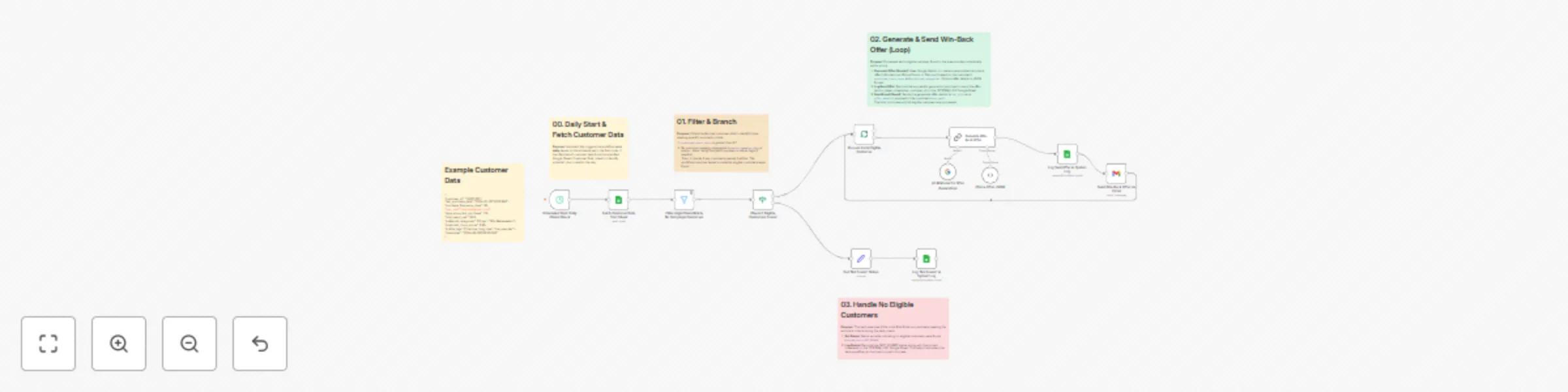
Automated daily customer win-back campaign with AI offers
Proactively retain customers predicted to churn with this automated n8n workflow. Running daily, it identifies high r...

Automated AI content creation & Instagram publishing from Google Sheets
Automated AI Content Creation & Instagram Publishing from Google Sheets This n8n workflow automates the creation and...
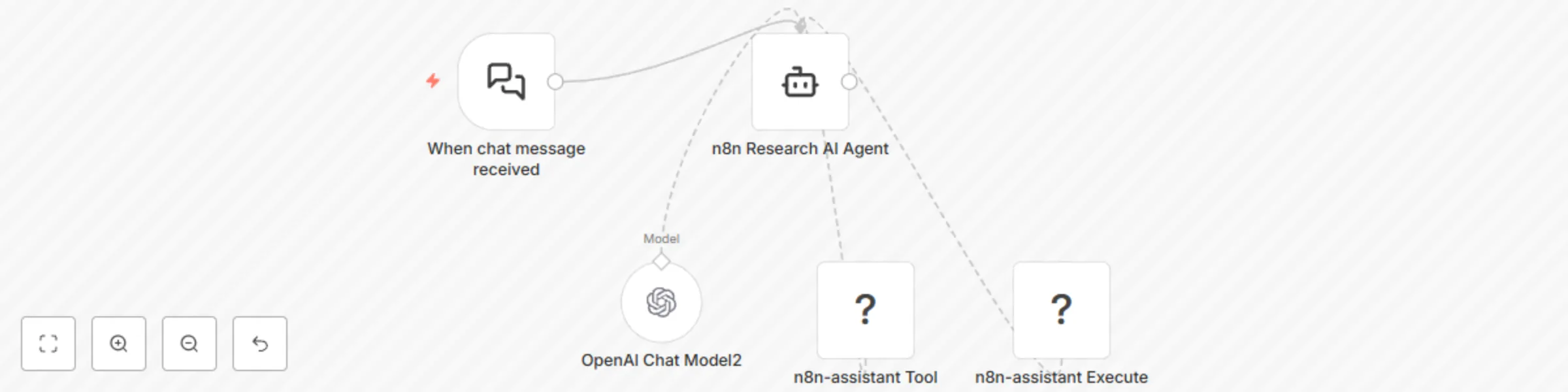
AI-powered research assistant for platform questions with GPT-4o and MCP
Description This workflow empowers you to effortlessly get answers to your n8n platform questions through an AI power...
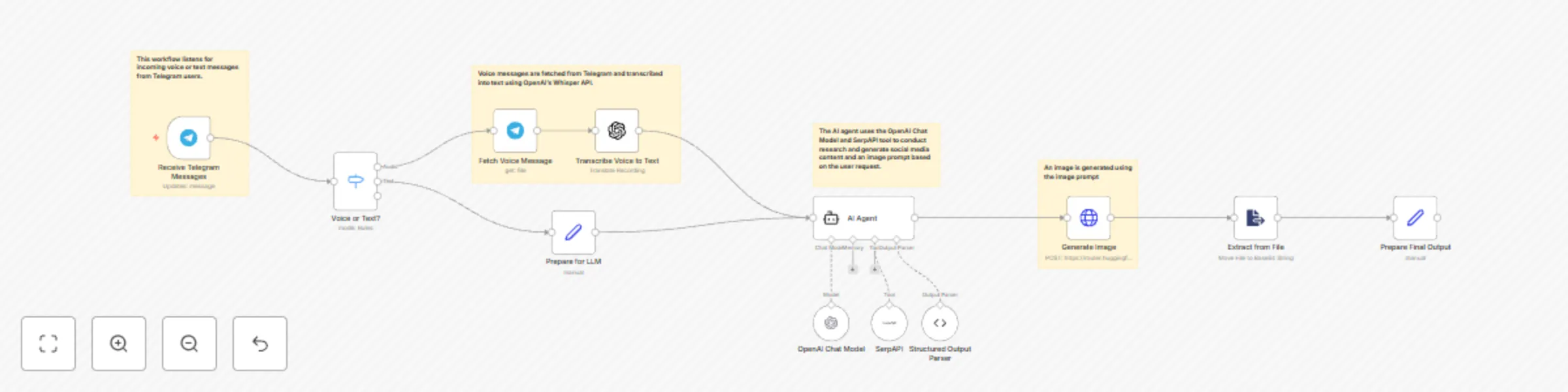
Create social media content from Telegram with AI
Description: Create Social Media Content from Telegram with AI This n8n workflow empowers you to effortlessly generat...
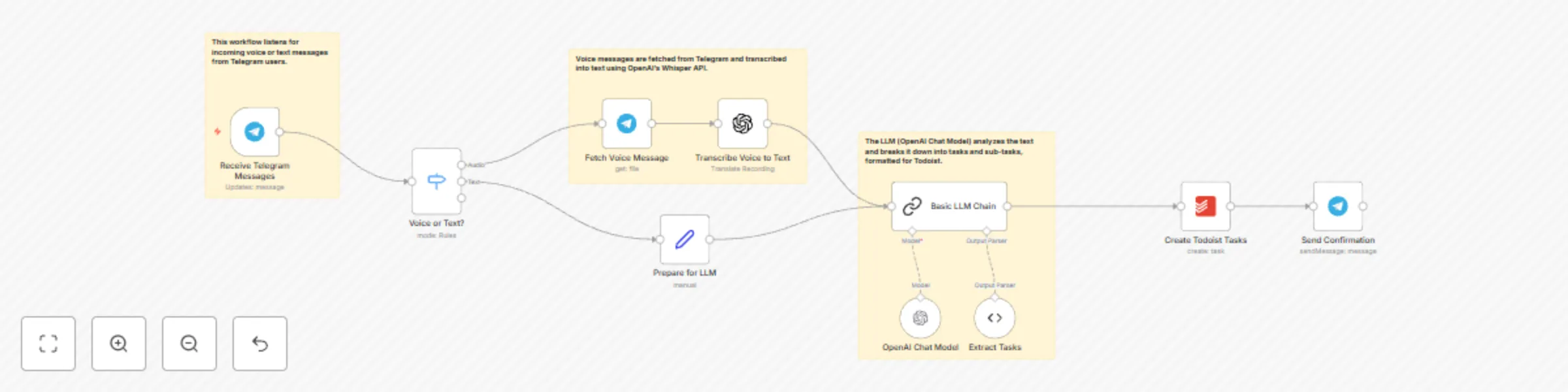
Effortless task management: Create Todoist tasks directly from Telegram with AI
Effortless Task Management: Create Todoist Tasks Directly from Telegram with AI This n8n workflow empowers you to sea...
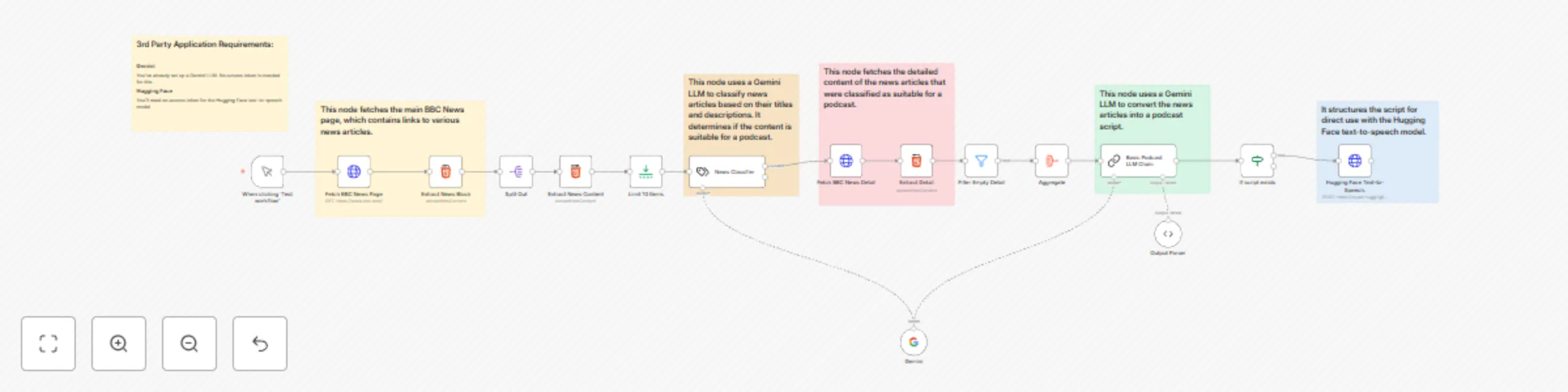
Turn BBC News articles into podcasts using Hugging Face and Google Gemini
Turn BBC News Articles into Podcasts using Hugging Face and Google Gemini Effortlessly transform BBC news articles in...