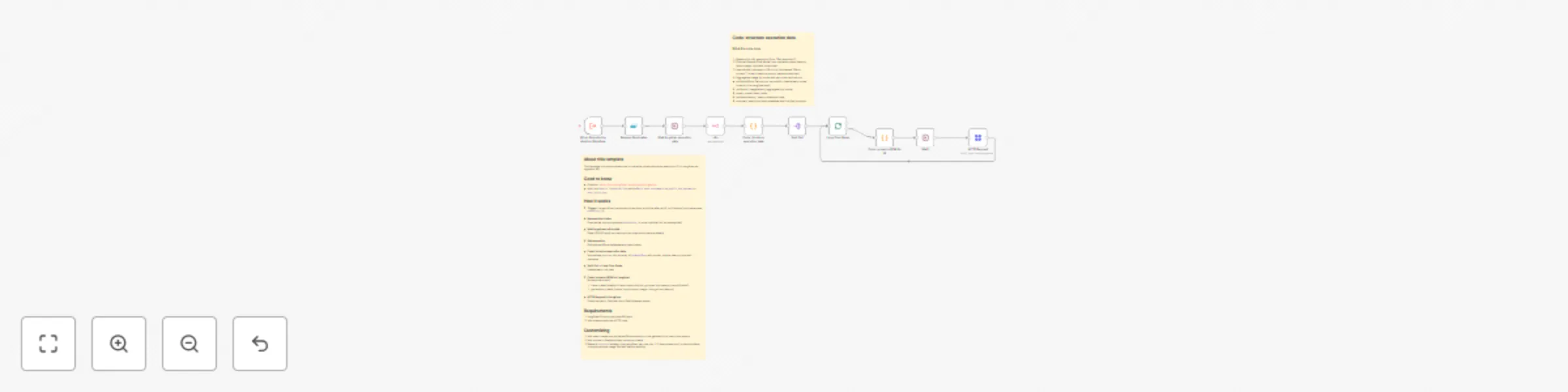
About this template This template is to demonstrate how to trace the observations per execution ID in Langfuse via in...