L
Lukas Kunhardt
2
Workflows
Workflows by Lukas Kunhardt
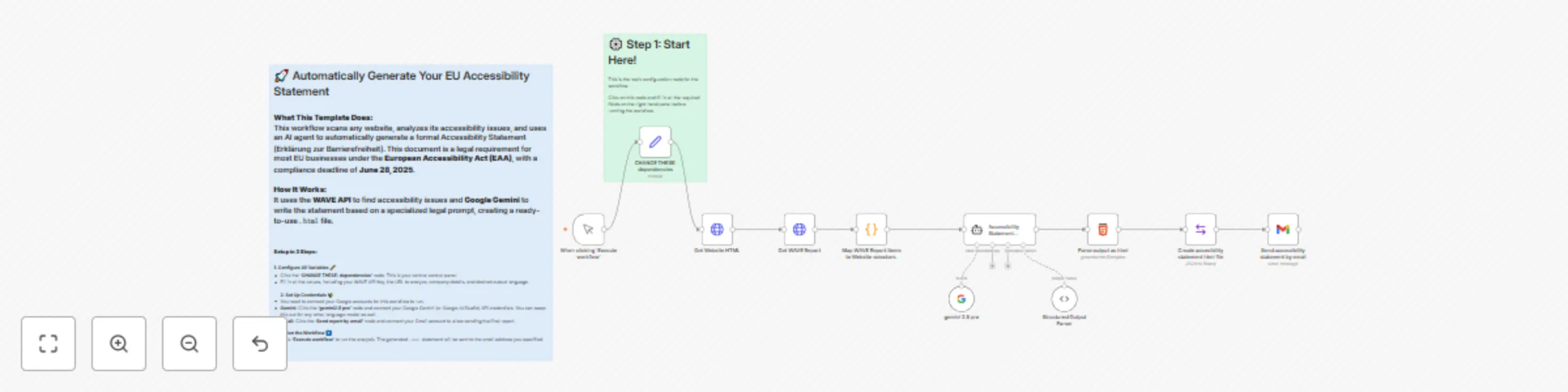
Free intermediate
Generate a legal website accessibility statement with AI and WAVE
Who is this for? This template is for any website owner, digital agency, or compliance officer operating within the E...
L
Lukas Kunhardt Document Extraction
7 Jun 2025
658
0

Free advanced
Segment PDFs by table of contents with Gemini AI and Chunkr.ai
Intelligently Segment PDFs by Table of Contents This workflow empowers you to automatically process PDF documents, in...
L
Lukas Kunhardt Document Extraction
5 Jun 2025
590
0