J
John Pranay Kumar Reddy
4
Workflows
Workflows by John Pranay Kumar Reddy

Free advanced
Kubernetes RCA and alerting using Gemini, Loki, Prometheus, Slack
Summary This n8n workflow automates Kubernetes root cause analysis (RCA) and incident alerting by integrating with Lo...
J
John Pranay Kumar Reddy AI Summarization
27 Aug 2025
101
0

Free advanced
Monitor Kubernetes services & pods with Prometheus and send alerts to Slack
🧩 Short Summary Proactively alert to service endpoint changes and pod/container issues (Pending, Not Ready, Restart...
J
John Pranay Kumar Reddy DevOps
21 Aug 2025
737
0
Free advanced
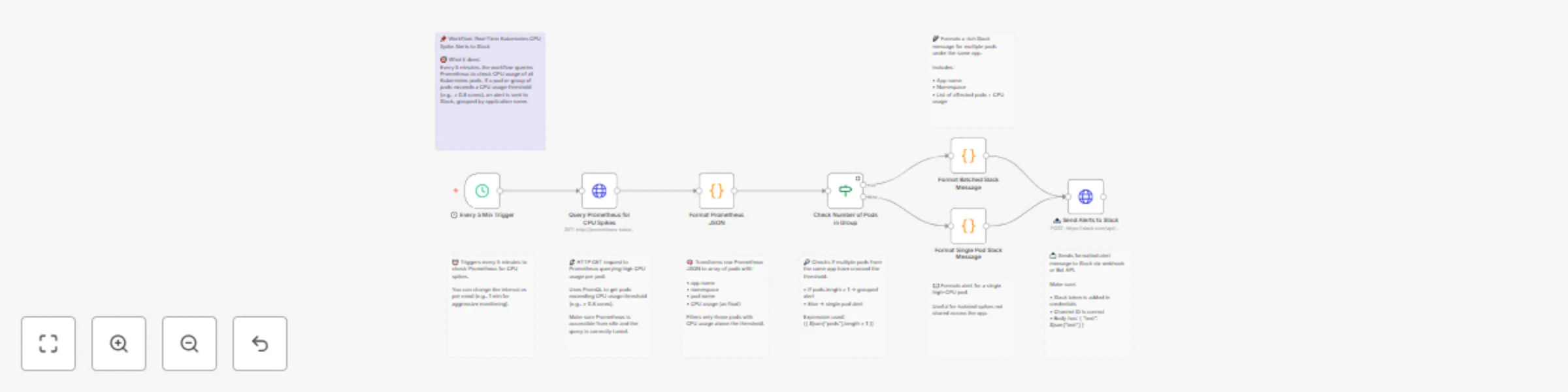
Send real-time Kubernetes(EKS/GKE/AKS) CPU spike alerts from Prometheus to Slack
🧾 Summary This workflow monitors Kubernetes pod CPU usage using Prometheus, and sends real time Slack alerts when CP...
J
John Pranay Kumar Reddy DevOps
8 Aug 2025
1064
0
Free intermediate
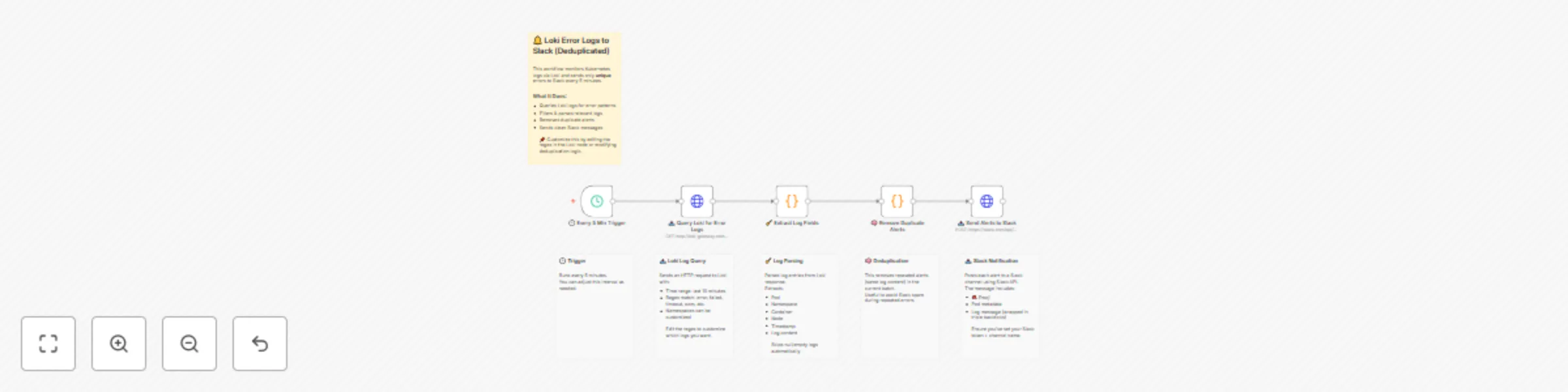
Send deduplicated Kubernetes(EKS/GKE/AKS) error logs from Grafana Loki to Slack
✨ Summary Efficiently monitor Kubernetes environments by sending only unique error logs from Grafana Loki to Slack. R...
J
John Pranay Kumar Reddy DevOps
6 Aug 2025
224
0