
Julian Kaiser
Workflows by Julian Kaiser

Monitor scheduled workflow health in n8n with automatic trigger checks
Automatically detect when your scheduled or polling trigger workflows stop running. Unlike error handlers that catch...
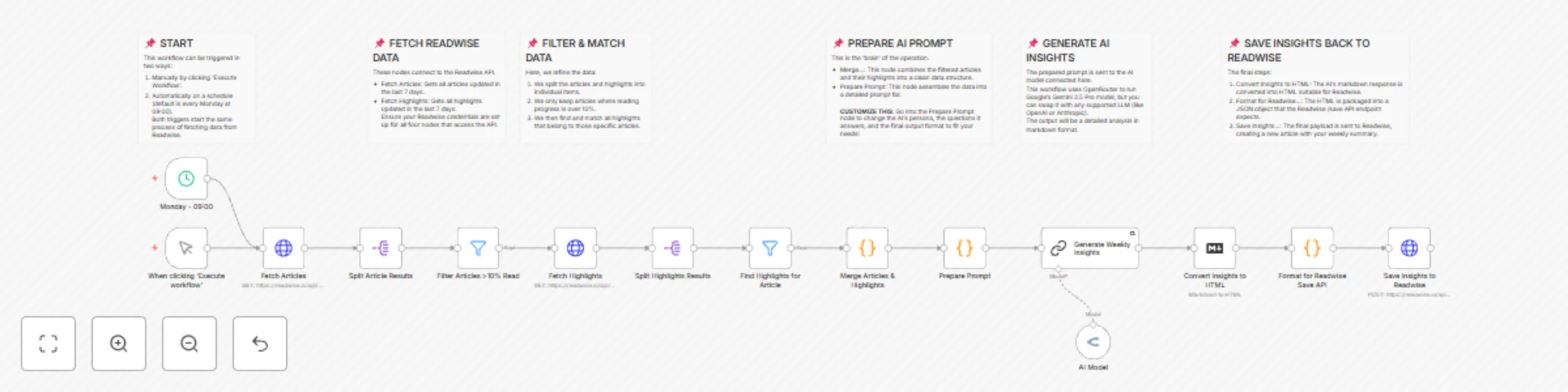
Transform Readwise highlights into weekly content ideas with Gemini AI
Turn Your Reading Habit into a Content Creation Engine This workflow is built for one core purpose: to maximize the r...
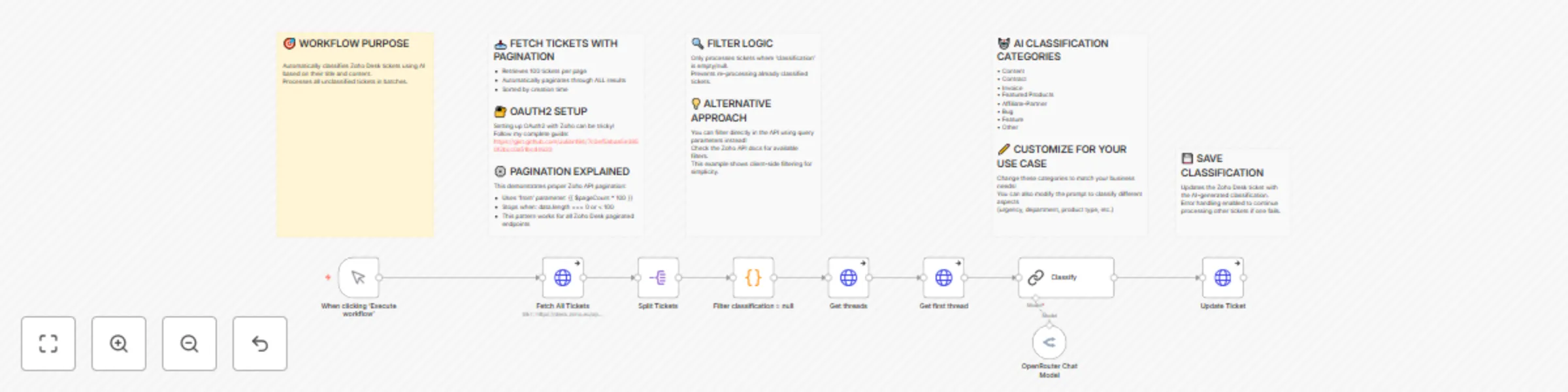
Automatically Classify Zoho Desk Support Tickets using Gemini AI
Automatically Classify Support Tickets in Zoho Desk with AI with Gemini Transform your customer support workflow with...

Automate Job Opportunity Digests with OpenRouter GPT-5 and Email
n8n Forum Job Aggregator AI Powered Email Digest Overview Automate your n8n community job board monitoring with this...
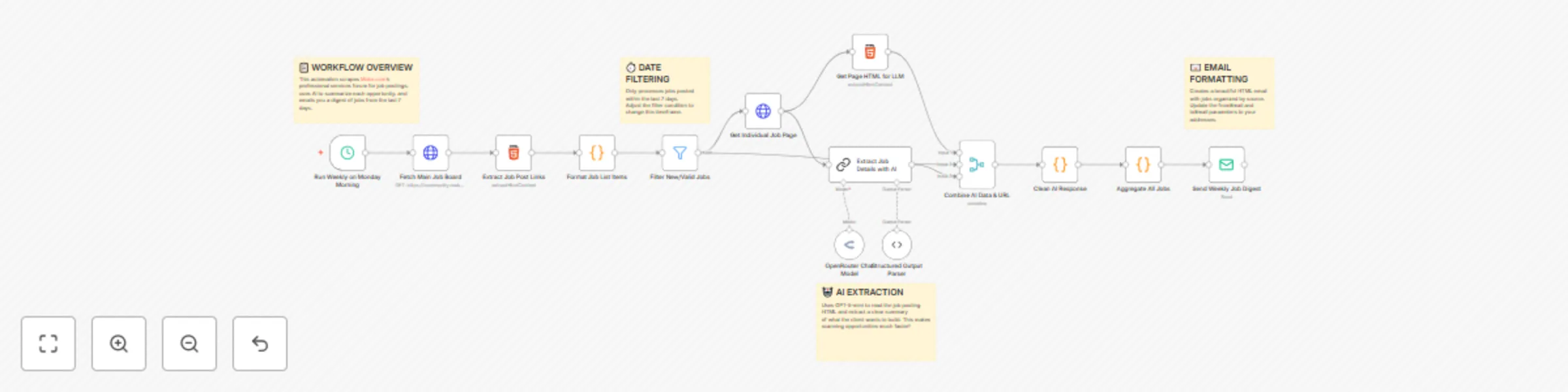
Automatically Scrape Make.com Job Board with GPT-5-mini Summaries & Email Digest
Automatically Scrape Make.com Job Board with GPT 5 mini Summaries & Email Digest Overview Who is this for? Make.com c...
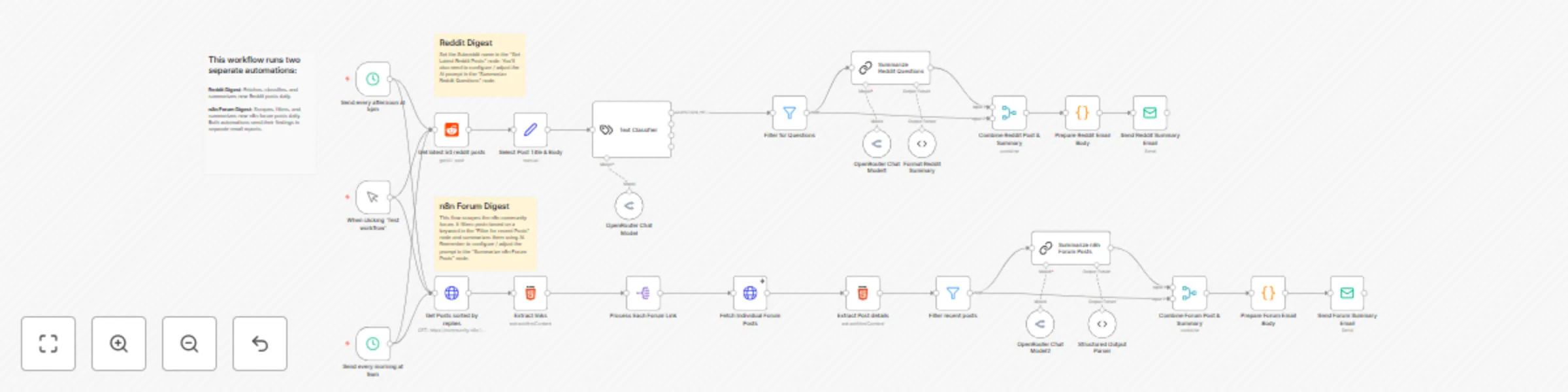
Community questions monitor with OpenRouter AI, Reddit & forum scraping
What problem does this solve? Earlier this year, as I got more involved with n8n, I committed to helping users on our...
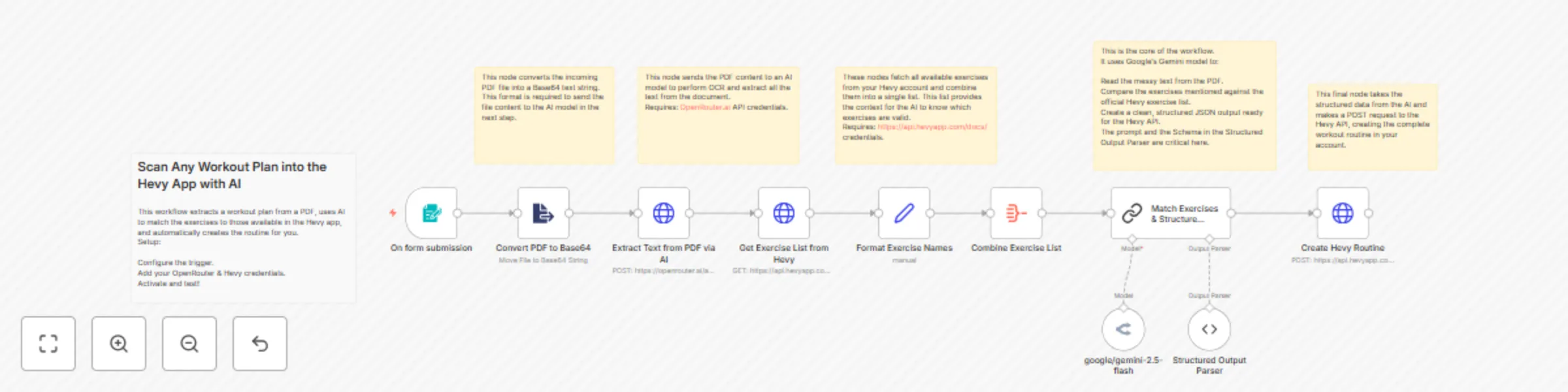
Convert workout plan PDFs to Hevy App routines with Gemini AI
Scan Any Workout Plan into the Hevy App with AI This workflow automates the creation of workout routines in the Hevy...
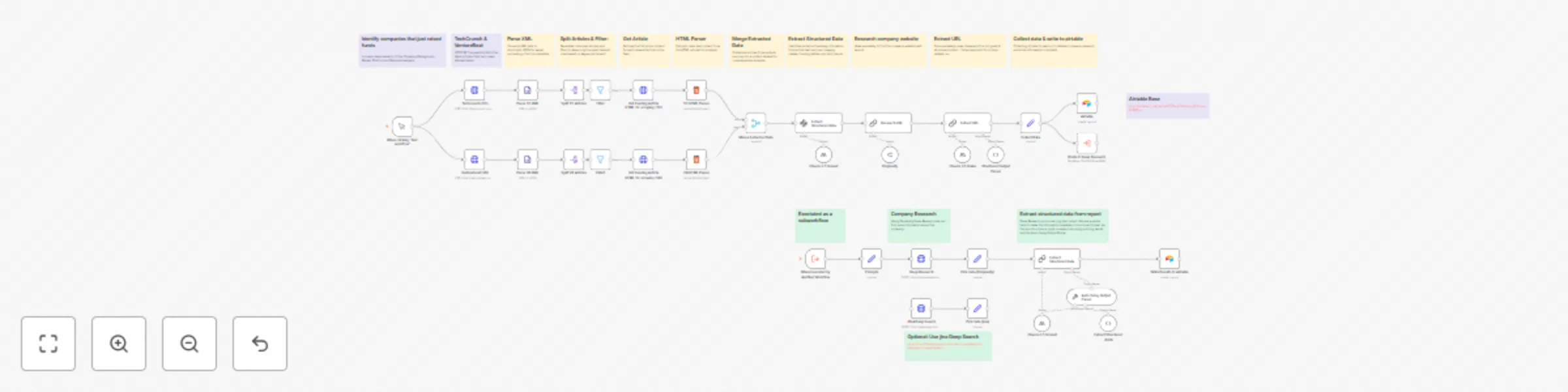
Startup funding research automation with Claude, Perplexity AI, and Airtable
Startup Funding Research Automation with Claude, Perplexity AI, and Airtable How it works This intelligent workflow a...

5 ways to process images & PDFs with Gemini AI in n8n
How it works Many users have asked in the support forum about different methods to analyze images and PDF documents w...
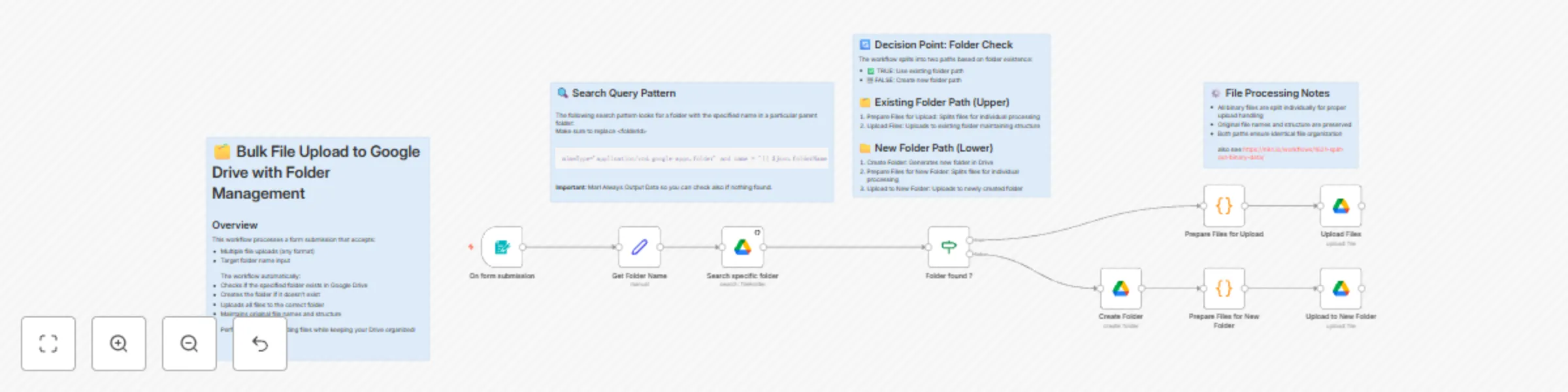
Bulk file upload to Google Drive with folder management
🗂️ Bulk File Upload to Google Drive with Folder Management How it works 1. User submits files and target folder name...
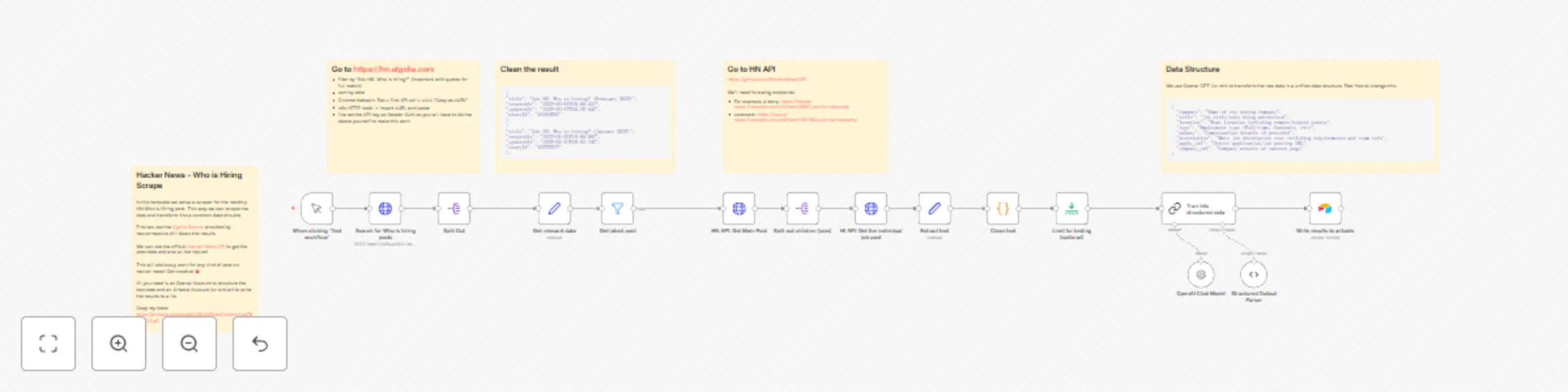
Hacker news job listing scraper and parser
This automated workflow scrapes and processes the monthly "Who is Hiring" thread from Hacker News, transforming raw j...