J
Jinash Rouniyar
3
Workflows
Workflows by Jinash Rouniyar
Free advanced
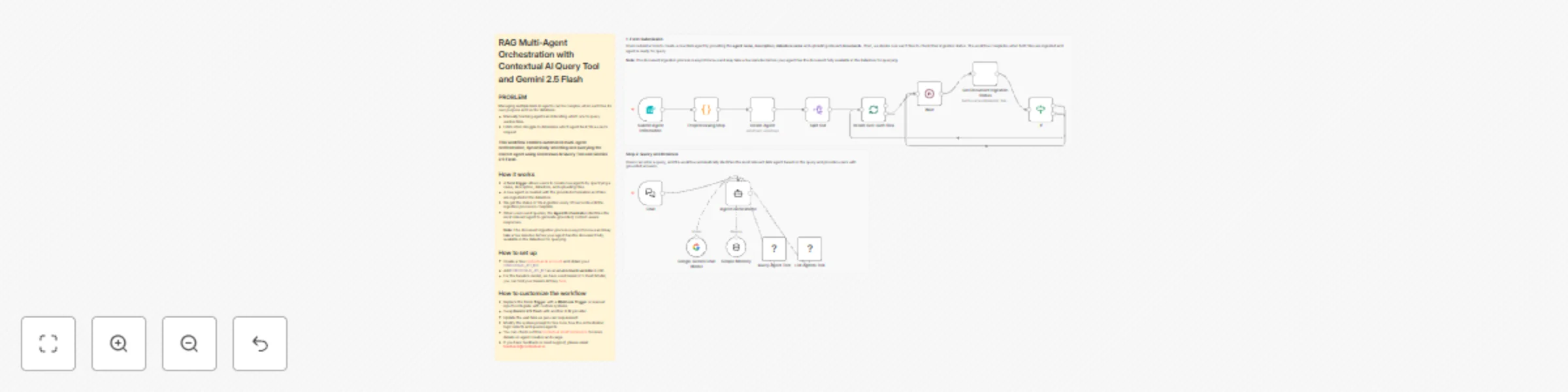
Automate Document Q&A with Multi-Agent RAG Orchestration using Contextual AI & Gemini
PROBLEM Managing multiple RAG AI agents can be complex when each has its own purpose and vector database. Manually tr...
J
Jinash Rouniyar Internal Wiki
9 Dec 2025
551
0
Free advanced
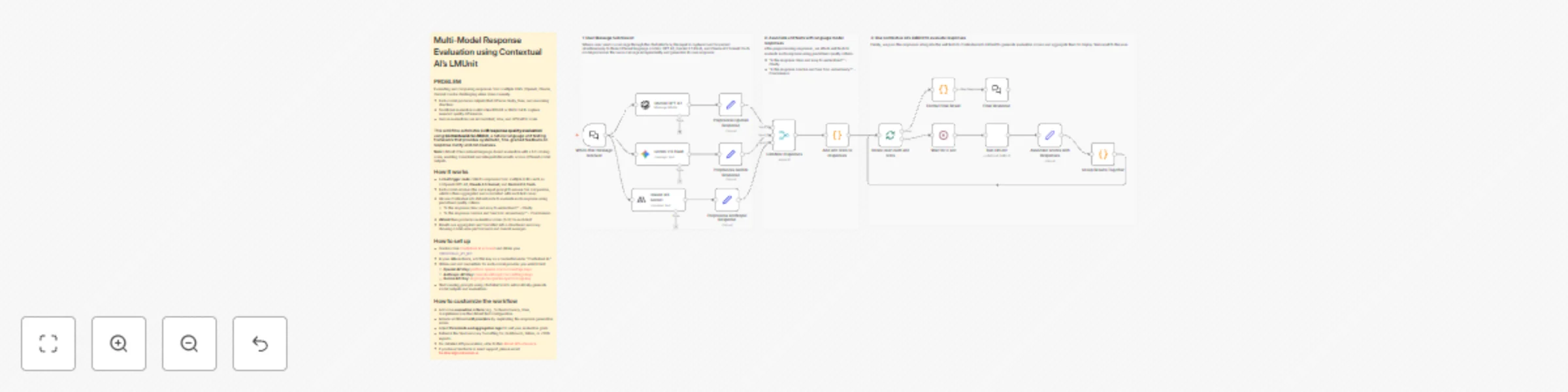
Compare GPT-4, Claude & Gemini Responses with Contextual AI's LMUnit Evaluation
PROBLEM Evaluating and comparing responses from multiple LLMs (OpenAI, Claude, Gemini) can be challenging when done m...
J
Jinash Rouniyar Engineering
9 Dec 2025
868
0
Free advanced
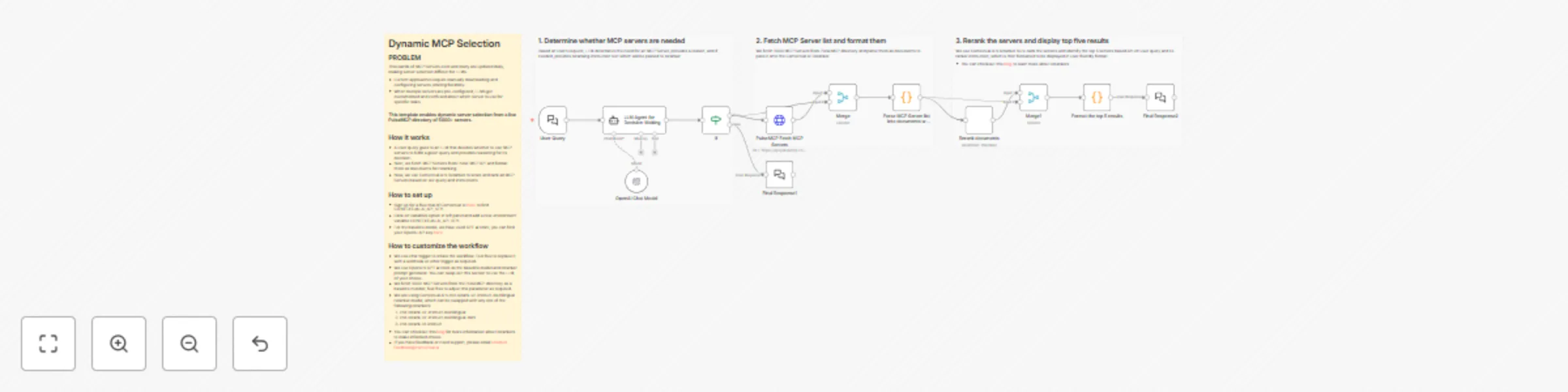
Dynamic MCP server selection with OpenAI GPT-4.1 and contextual AI reranker
PROBLEM Thousands of MCP Servers exist and many are updated daily, making server selection difficult for LLMs. Curren...
J
Jinash Rouniyar Engineering
5 Sep 2025
285
0