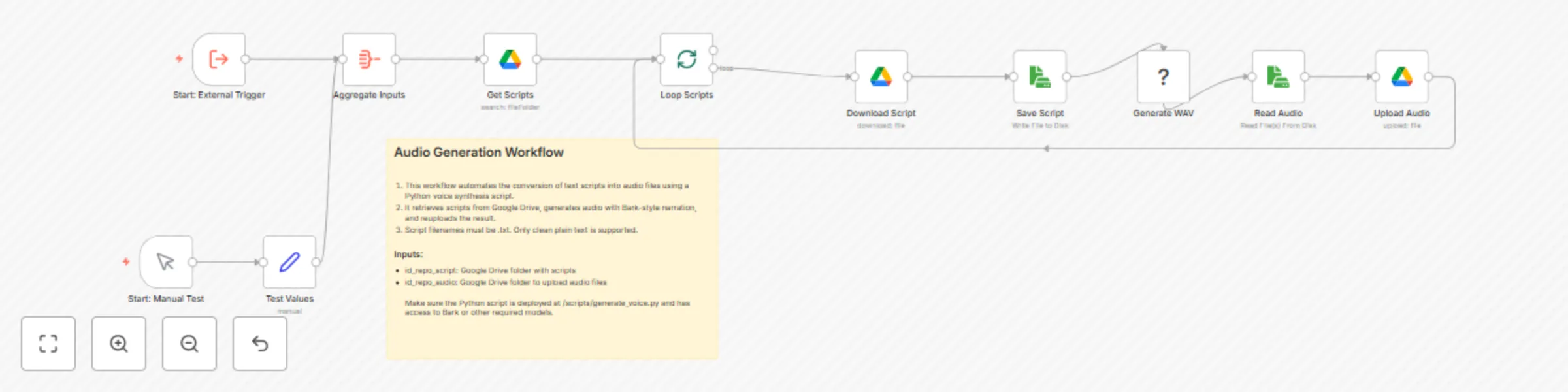
Audio Generator – Documentation 🎯 Purpose: Generate audio files from text scripts stored in Google Drive. 🔁 Flow: 1...