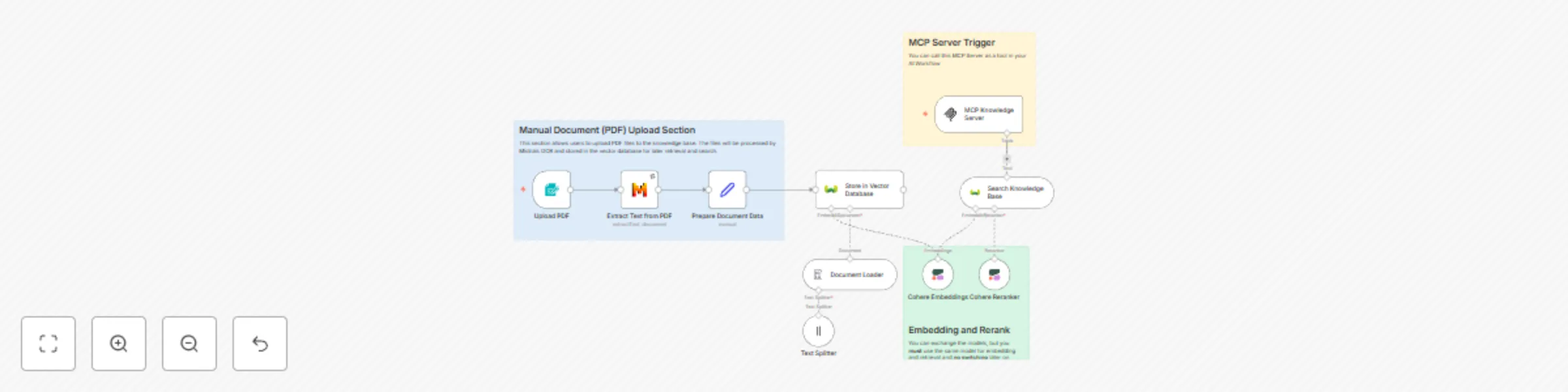
Build a PDF to Vector RAG System: Mistral OCR, Weaviate Database and MCP Server A comprehensive RAG (Retrieval Augmen...