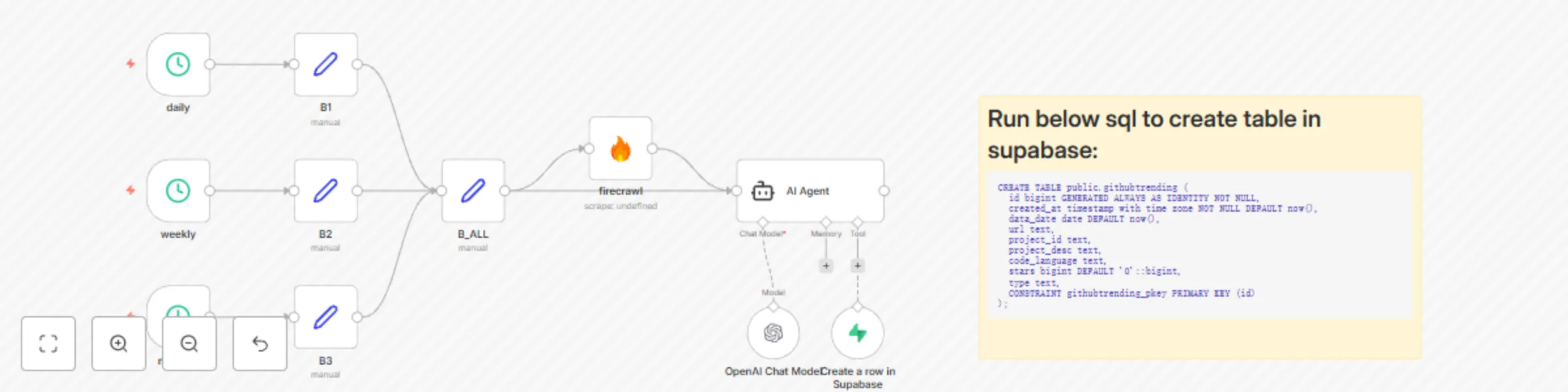
GitHub Trending to Supabase (Daily, Weekly, Monthly) Who is this for? This workflow is for developers, researchers, f...