B
Br1
2
Workflows
Workflows by Br1

Free advanced
Build RAG-powered support agent for Jira issues using Pinecone and OpenAI
Load Jira open issues with comments into Pinecone + RAG Agent (Direct Tool or MCP) Who’s it for This workflow is desi...
B
Br1 Support Chatbot
18 Sep 2025
387
0
Free advanced
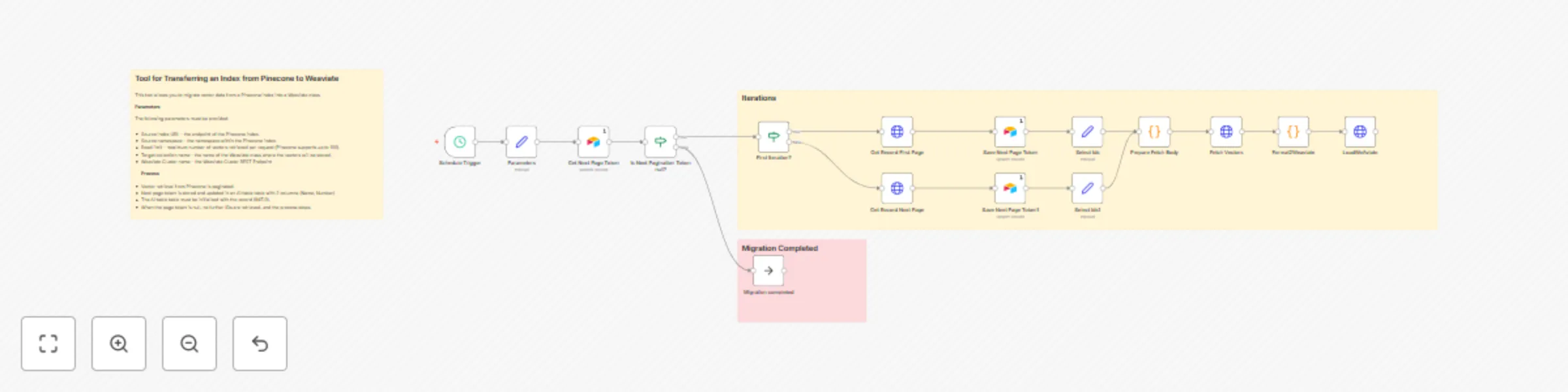
Migrate Pinecone index to Weaviate class with Airtable pagination
Who’s it for This workflow is designed for developers, data engineers, and AI teams who need to migrate a Pinecone Cl...
B
Br1 Engineering
10 Sep 2025
90
0