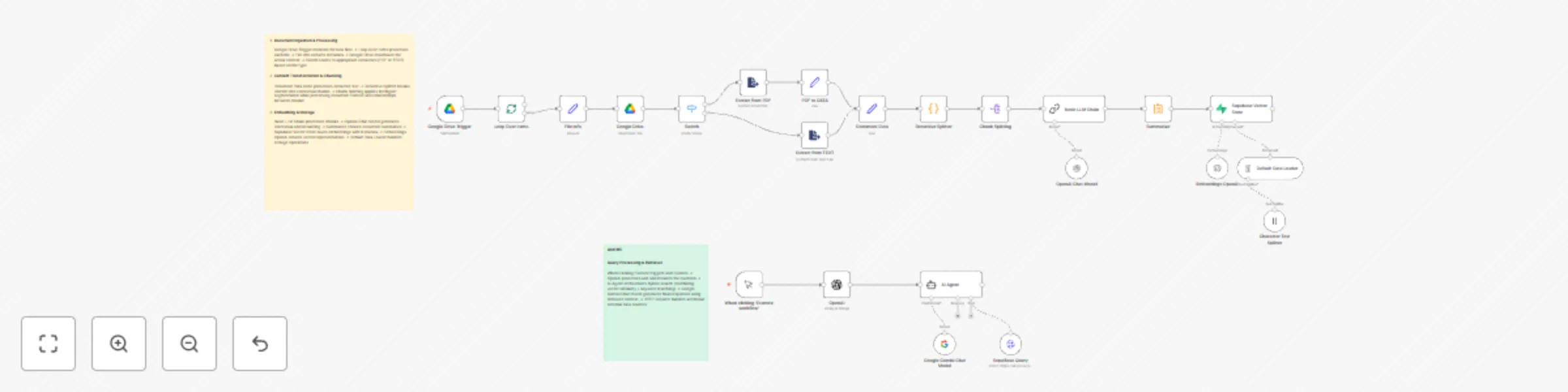
1. Document Ingestion & Processing Google Drive Trigger monitors for new files → Loop Over Items processes each file...