A
automedia
4
Workflows
Workflows by automedia

Free advanced
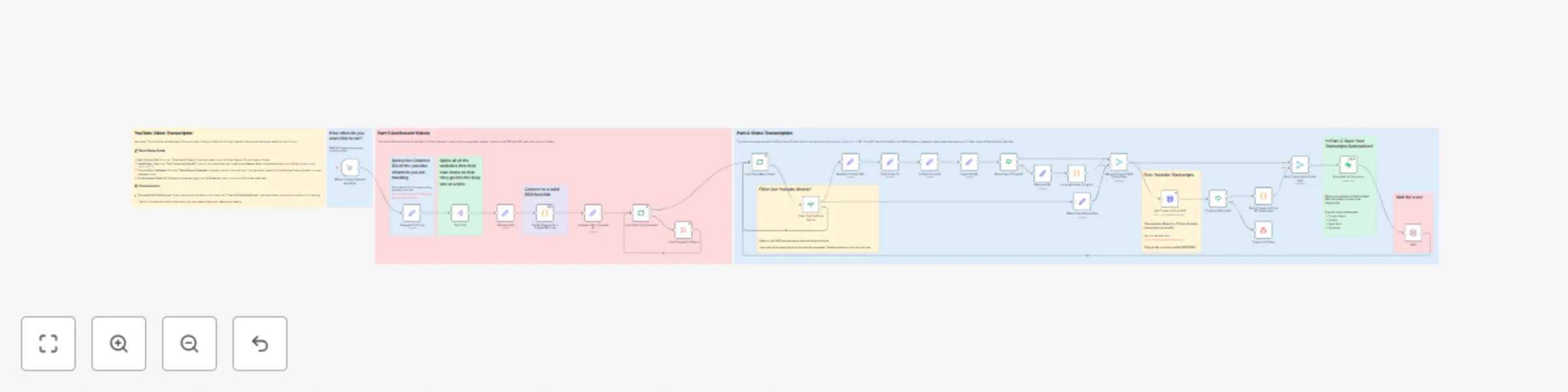
Scheduled YouTube transcription with de-duplication using Transcript.io and Supabase
Scheduled YouTube Transcription with Duplicate Prevention Who's It For? This template is for advanced users, content...
a
automedia Document Extraction
16 Oct 2025
139
0
Free advanced
Transcribe Youtube videos for free with youtube-transcript.io & save to Supabase
Transcribe New YouTube Videos and Save to Supabase Who's It For? This workflow is for content creators , marketers ,...
a
automedia Document Extraction
16 Oct 2025
845
0
Free advanced
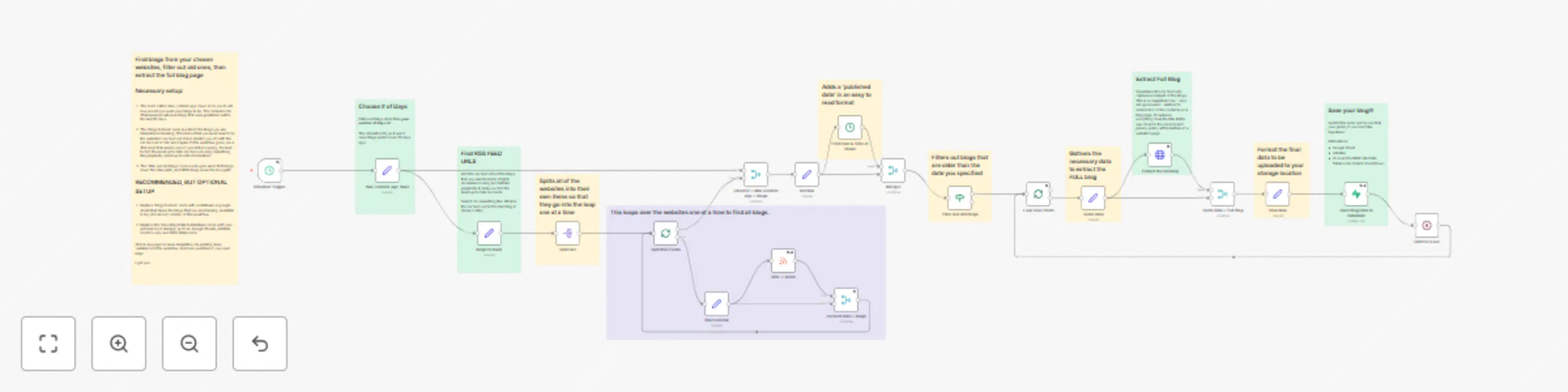
Monitor RSS feeds, extract full articles with Jina AI, and save to Supabase
Monitor RSS Feeds, Extract Full Articles, and Save to Supabase Overview This workflow solves a common problem with RS...
a
automedia Document Extraction
14 Oct 2025
212
0
Free advanced
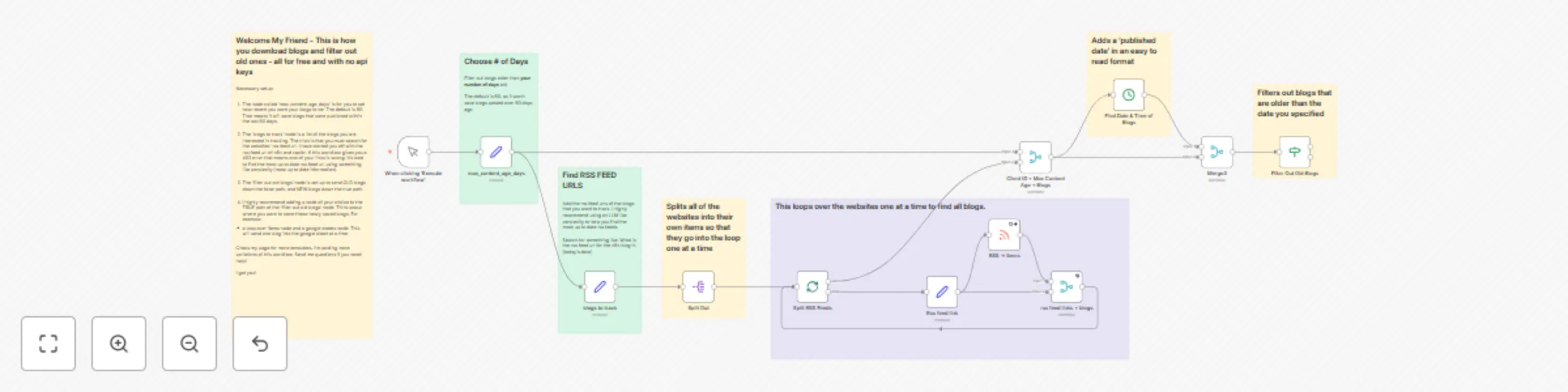
Automated blog content tracking with RSS feeds and time-based filtering
Automated Blog Monitoring System with RSS Feeds and Time Based Filtering Overview This workflow provides a powerful y...
a
automedia Market Research
14 Oct 2025
141
0