A
Askan
2
Workflows
Workflows by Askan
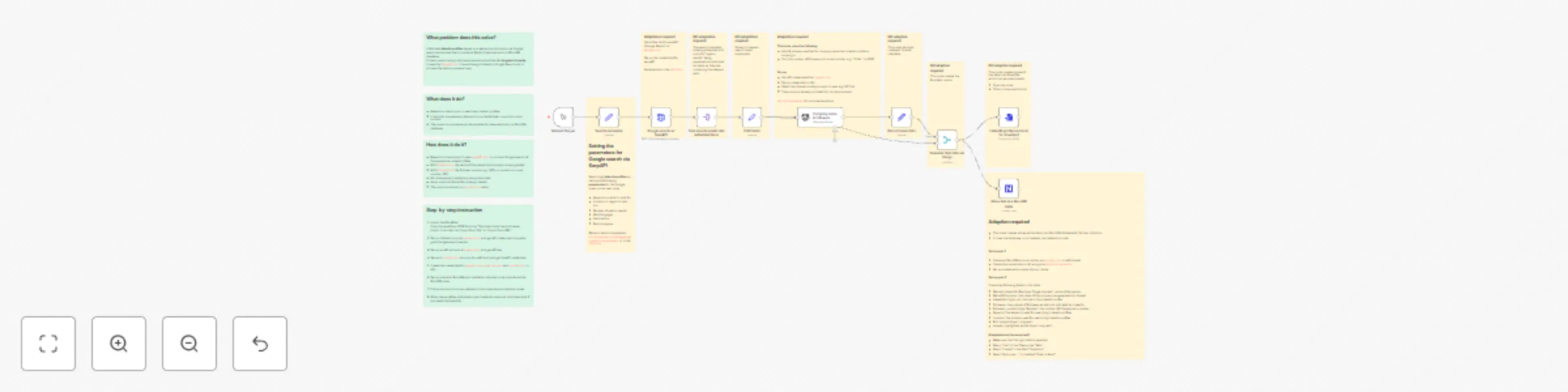
Free advanced
Collect LinkedIn profiles with AI processing using SerpAPI, OpenAI, and NocoDB
What problem does this solve? It fetches LinkedIn profiles for a multitude of purposes based on a keyword and locatio...
A
Askan Lead Generation
7 May 2025
1823
0
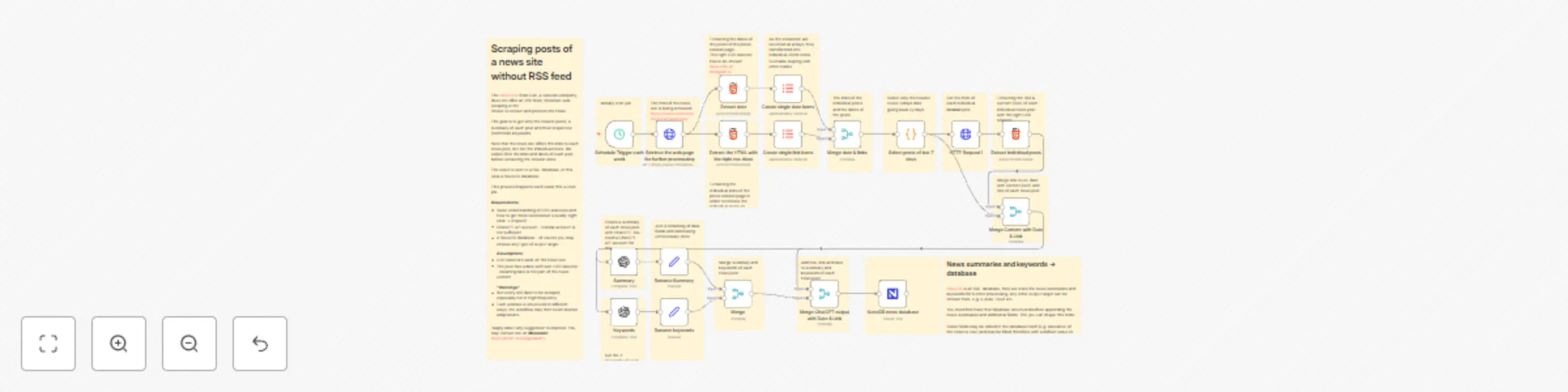
Free advanced
Scrape and summarize posts of a news site without RSS feed using AI and save them to a NocoDB
The News Site from Colt, a telecom company, does not offer an RSS feed, therefore web scraping is the choice to extra...
A
Askan Market Research
18 Mar 2024
29636
0