
Alok Kumar
6
Workflows
Workflows by Alok Kumar
Free advanced
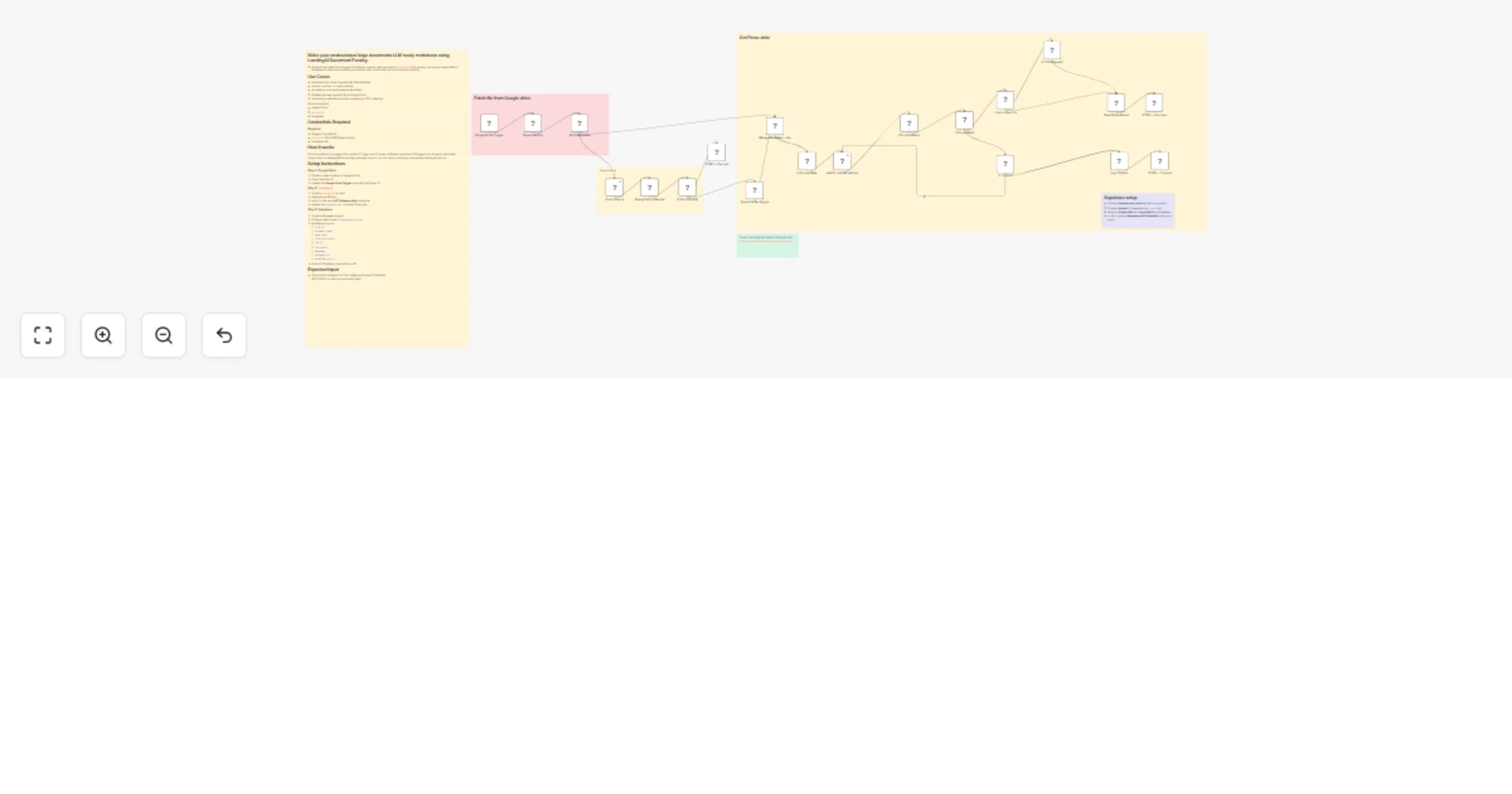
Parse Google Drive documents to RAG-ready Markdown with Landing.ai and Supabase cache
Make your unstructured large documents LLM ready markdown using LandingAI Document Parsing. Automatically watches a G...
Document Extraction
6 Feb 2026
17
0
Free advanced
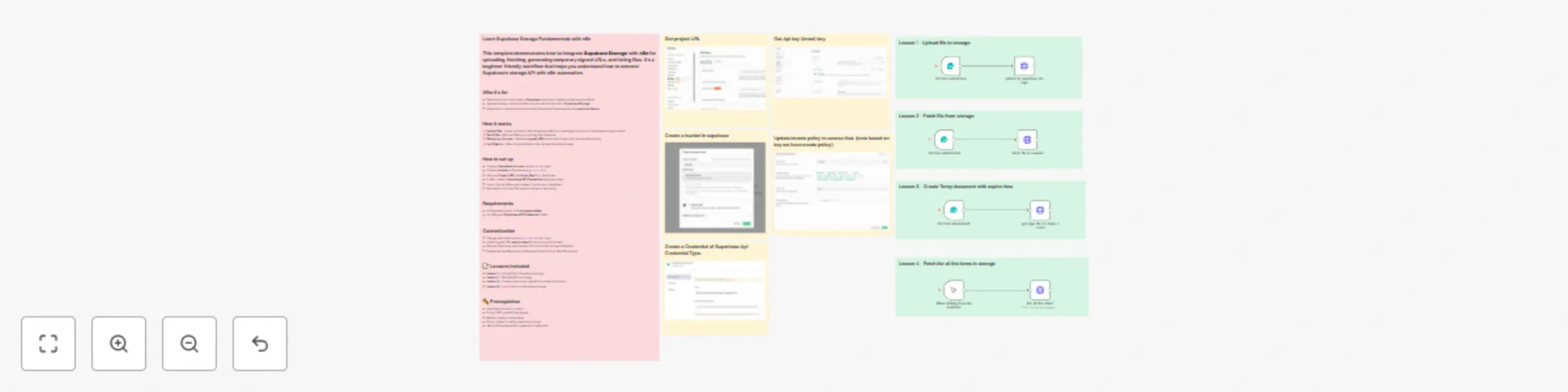
Supabase storage tutorial: Upload, fetch, sign & list files
Learn Supabase Storage Fundamentals with n8n This template demonstrates how to integrate Supabase Storage with n8n fo...
File Management
4 Sep 2025
635
0

Free advanced
Automate document approvals with multi-level workflows using Supabase & Gmail
Multi Level Document Approval & Audit Workflow This workflow automates a document approval process using Supabase and...
Document Extraction
2 Sep 2025
467
0
Free intermediate
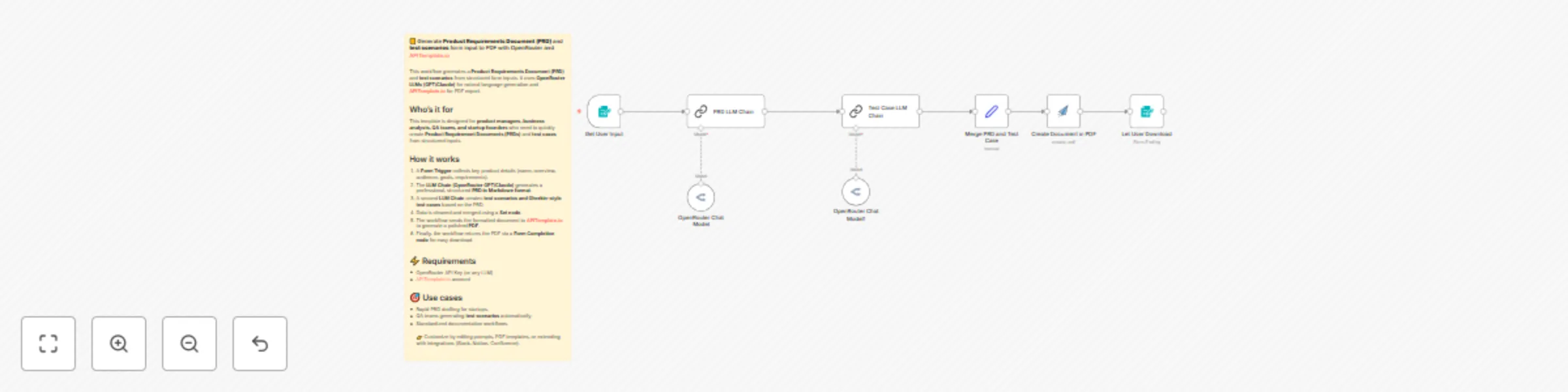
Generate PRDs and test scenarios with GPT/Claude and PDF export
📒 Generate Product Requirements Document (PRD) and test scenarios form input to PDF with OpenRouter and APITemplate....
Document Extraction
31 Aug 2025
819
0

Free advanced
Website content chatbot with Pinecone, Airtable & OpenAI for RAG applications
This n8n workflow shows how to extract website content, index it in Pinecone, and leverage Airtable to power a chat a...
AI RAG
28 Aug 2025
918
0

Free advanced
Build a PDF Q&A system with LlamaIndex, OpenAI embeddings & Pinecone vector DB
Parse, Normalize, Extract, and Store PDF Content for RAG in Pinecone This workflow automates a full RAG pipeline for...
AI RAG
22 Aug 2025
551
0